

Stable Diffusion 3.5 Medium 登場! 盛り上がる開発者コミュニティ、LoRAやSkip Layer Guidance (SLG)で指も改善?

2024年10月29日(日本時間)、Stability AIから予告通り、最新の画像生成モデル「Stable Diffusion 3.5 Medium」がオープンリリースされました。
🚀Stable Diffusion 3.5 Medium が登場しました!
— Stability AI Japan (@StabilityAI_JP) October 29, 2024
このオープンモデルは、25億のパラメータを持ち、消費者向けハードウェア上で「箱から出してすぐに」動作するように設計されています。
ブログにMediumの内容を追加しています。ぜひご覧ください。https://t.co/6Er2CRVTEl pic.twitter.com/CxdTuFA5ws
Stable Diffusion 3.5 Medium が登場しました!
このオープンモデルは、25億のパラメータを持ち、消費者向けハードウェア上で「箱から出してすぐに」動作するように設計されています。
ブログにMediumの内容を追加しています。ぜひご覧ください。
「消費者向けハードウェア…!?」というドヨメキがAICU media編集部に響き渡ったのですが、Stability AI公式が具体的なモデル名とGPU製品名で推奨動作表を提供しています。
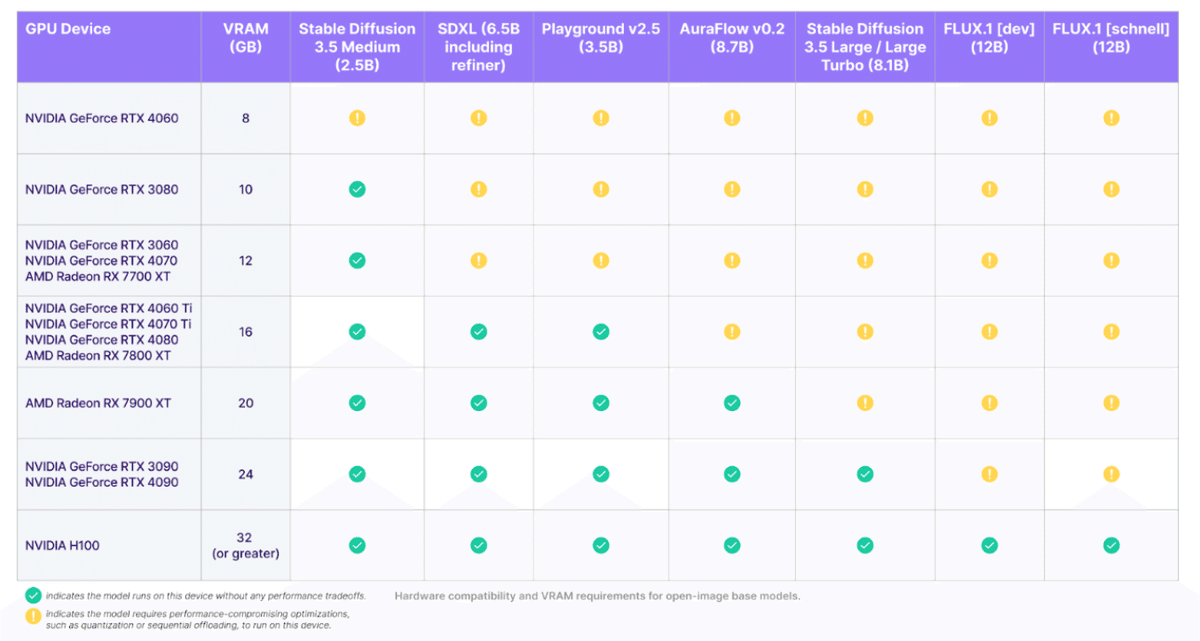
Stable Diffusion 3.5 Medium (以下、SD3.5M) は 2.5B(25億パラメータ)のモデルであり、NVIDIA GeForce RTX 3080 (VRAM 10GB以上) が推奨になっています。NVIDIA GeForce RTX 4060 (VRAM 6GB)では、[!] という黄色いマークがつけられており、「[!] indicates the model requires performance - compromising optimizations, such as quantization or sequential offloading, to run on this device.」(モデルをこのデバイスで実行するには、量子化や順次オフロードなどのパフォーマンスを犠牲にした最適化が必要であることを示します)と書かれています。
ダウンロードはこちらから、ファイルサイズは4.75GBです。
なお、SD3.5 Large (80億パラメータ)も配布されています(ファイルサイズとしては16.5GB!です)。動作させるには32GB VRAMを搭載した NVIDIA H100クラスのGPUが必要とのことです。
https://huggingface.co/stabilityai/stable-diffusion-3.5-large/blob/main/sd3.5_large.safetensors
Google Colab上でweightをダウンロードするテクニック!
Google Colab上で、HuggingFaceに置かれたStable Diffusion 3.5 MediumやLargeを活用したい!でもHuggingFaceでの認証が通らないのでwgetすることができない…なんて諦めてしまったひとはいませんか?
AICU AIDX Labではこんな方法で、自動でダウンロードできるスクリプトを組んでいます。
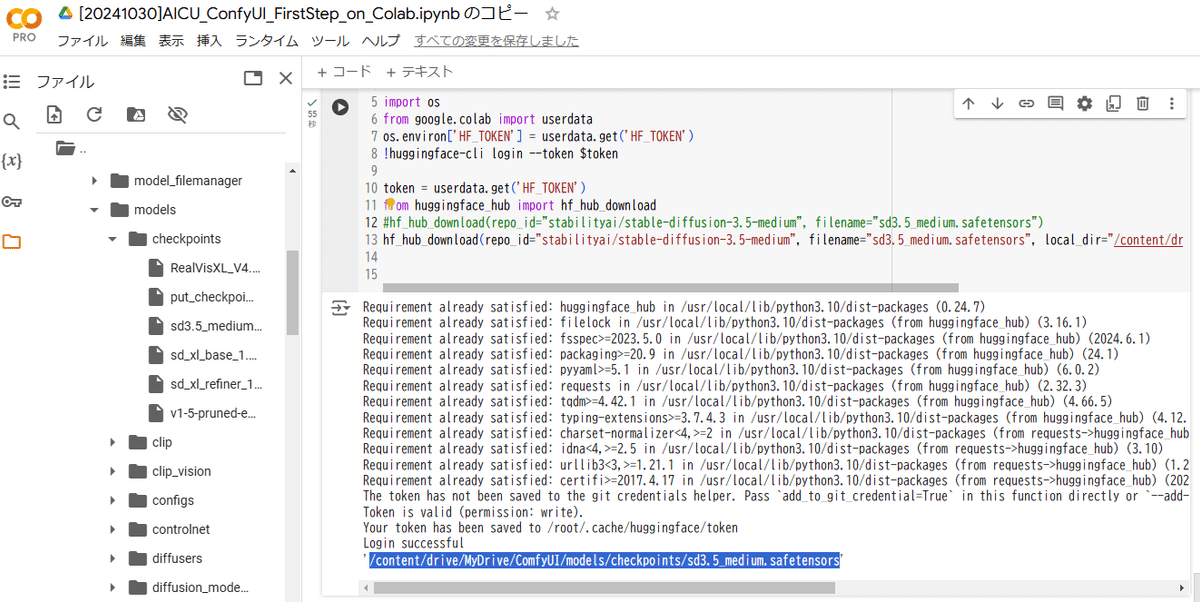
まずはGoogle Colabの「シークレット機能」を使って、HuggingFaceのAPIキーを保存します。ここでは「HF_TOKEN」という名前にしてあります。

Google Colabノートブック上でこちらのHF_TOKENにアクセスを許可して、以下のようなコードを書きます。
#!wget -c https://huggingface.co/stabilityai/stable-diffusion-3.5-medium/resolve/main/sd3.5_medium.safetensors -P ./models/checkpoints
# %cd /content/drive/MyDrive/ComfyUI/models/checkpoints
!pip install huggingface_hub
import os
from google.colab import userdata
os.environ['HF_TOKEN'] = userdata.get('HF_TOKEN')
!huggingface-cli login --token $token
token = userdata.get('HF_TOKEN')
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="stabilityai/stable-diffusion-3.5-medium", filename="sd3.5_medium.safetensors", local_dir="/content/drive/MyDrive/ComfyUI/models/checkpoints")
hf_hub_download(repo_id="stabilityai/stable-diffusion-3.5-medium", filename="sd3.5_medium.safetensors", local_dir="/content/drive/MyDrive/ComfyUI/models/checkpoints")
と書くことで、HuggingFaceにログインした状態でファイルを指定ディレクトリに直接ダウンロードできます!これは便利。
参考:その他のHuggingFaceの使いこなしはこの記事でも扱っています。
盛り上がる開発者コミュニティ
AICU media編集部でもSD3.5のリリース直後から評価に入っています。
日本人などの人種や肌の多様性は確認できましたが、一方で「指の正確さ」については難があるという印象を得ましたが、実はその後、急速にコミュニティ内で改善が見られるので共有したいと思います。
まずは、sampler をEuler Ancestral (Euler_a) にする!
集合知的に様々なノウハウが集まってきていますが、SD3.5でMMDiT-Xにモデルが変わっていることもあり、サンプラーについても見直しが必要なようです。
指に関しては、Euler Ancestral (Euler_a)がよいという説があります。
世界のKohya氏、LoRA対応を追加。
LoRA学習スクリプト「sd-scripts」を開発し、世界中のStable Diffusionコミュニティの英雄ともいえるKohya氏がSD3.5M対応をGitHubリポジトリにプッシュしました。
sd-scriptsのSD3.5対応ブランチにSD3.5M対応を追加しました。https://t.co/10DbeJ5FZZ
— Kohya Tech (@kohya_tech) October 30, 2024
コメントでは世界中の開発者からの検証結果が寄せられ始めています。
Civitaiによるマニュアル・ワークフローの提供
SD3公開直後、荒れた瞬間があったCivitaiコミュニティですが、SD3.5については公式のエデュケーションブログやワークフローの公開が提供されています。
せっかくなので翻訳を提供していきたいと思います。最新のモデルと専門用語を学ぶうえでも大変役に立ちます。
Stable Diffusion 3.5 Mediumクイックスタートガイド
Stable Diffusion 3.5 Mediumは、画質、タイポグラフィ、複雑なプロンプトの理解、リソース効率の向上を実現する、マルチモーダル拡散トランスフォーマー(MMDiT-x)をベースにしたテキスト画像生成モデルです。
注記: このモデルはStability Community Licenseの下でリリースされています。商用ライセンスについては、Stability AIのサイトをご覧いただくか、当社までお問い合わせください。
モデルの説明
開発元: Stability AI
モデルの種類: MMDiT-Xテキスト画像生成モデル
モデルの説明: このモデルは、テキストプロンプトに基づいて画像を生成します。3つの固定の事前学習済みテキストエンコーダー、トレーニングの安定性を向上させるためのQK正規化、および最初の12個のトランスフォーマーレイヤーにおけるデュアルアテンションブロックを使用する改良版マルチモーダル拡散トランスフォーマー(https://arxiv.org/abs/2403.03206)です。
ライセンス
コミュニティライセンス: 年間総収益が100万ドル未満の組織または個人の研究、非商用、および商用利用は無料です。詳細はコミュニティライセンス契約をご覧ください。https://stability.ai/license で詳細をご覧ください。
年間収益が100万ドルを超える個人および組織の場合:エンタープライズライセンスを取得するには、当社までお問い合わせください。
実装の詳細
MMDiT-X: トランスフォーマーの最初の13レイヤーに自己注意モジュールを導入し、マルチ解像度生成と全体的な画像の整合性を強化します。
QK正規化: トレーニングの安定性を向上させるためにQK正規化技術を実装します。
混合解像度トレーニング:
プログレッシブトレーニングステージ:256→512→768→1024→1440の解像度
最終段階には、マルチ解像度生成パフォーマンスを向上させるための混合スケール画像トレーニングが含まれていました
低解像度ステージでは、位置埋め込み空間を384x384(潜在)に拡張
混合解像度とアスペクト比の全範囲にわたるトランスフォーマーレイヤーの堅牢性を強化するために、位置埋め込みにランダムクロップ拡張を採用しました。たとえば、64x64の潜在画像が与えられた場合、トレーニング中に192x192の埋め込み空間からランダムにクロップされた64x64の埋め込みをxストリームへの入力として追加します。
これらの機能強化は、マルチ解像度画像生成、一貫性、および様々なテキスト画像タスクへの適応性におけるモデルのパフォーマンス向上に総合的に貢献しています。
テキストエンコーダー:
CLIP:OpenCLIP-ViT/G、CLIP-ViT/L、コンテキスト長77トークン
T5:T5-xxl、トレーニングのさまざまな段階でのコンテキスト長77/256トークン
トレーニングデータと戦略:
このモデルは、合成データやフィルタリングされた公開データなど、様々なデータでトレーニングされました。
元のMMDiTアーキテクチャの技術的な詳細については、研究論文を参照してください。
使用方法と制限事項
このモデルは長いプロンプトを処理できますが、T5トークンが256を超えると、生成された画像の端にアーティファクトが発生する場合があります。ワークフローでこのモデルを使用する場合はトークン制限に注意し、アーティファクトが目立ちすぎる場合はプロンプトを短くしてください。
MediumモデルはLargeモデルとはトレーニングデータの分布が異なるため、同じプロンプトに同じように反応しない場合があります。
より良い構造と解剖学的整合性を得るためには、Skip Layer Guidanceを使ったサンプリングを推奨します。
実装の詳細
MMDiT-X: トランスフォーマーの最初の13層に自己関心モジュールを導入し、マルチ解像度生成と全体的なイメージの一貫性を強化。
QK正規化: トレーニングの安定性を向上させるために、QK正規化技術を導入。
混合解像度トレーニング:
段階的なトレーニングステージ:256 → 512 → 768 → 1024 → 1440解像度
最終段階では、マルチ解像度生成性能を高めるために、混合スケール画像のトレーニングを実施
低解像度段階では、位置埋め込み空間を384x384(潜在)に拡張
混合解像度およびアスペクト比の全範囲にわたってトランスフォーマー層の頑健性を強化するために、位置埋め込みにランダムなクロップ拡張を採用しました。例えば、64x64の潜在画像が与えられた場合、192x192の埋め込み空間からランダムにクロップした64x64の埋め込みを、xストリームへの入力としてトレーニング中に追加します。
これらの強化により、多様なテキストから画像へのタスクにおける、マルチ解像度の画像生成、一貫性、適応性の向上というモデルのパフォーマンス改善に総合的に貢献しています。
テキストエンコーダー:
CLIPs: OpenCLIP-ViT/G、CLIP-ViT/L、文脈の長さ77トークン
T5: T5-xxl、トレーニングの異なる段階における文脈の長さ77/256トークン
トレーニングデータと戦略:
このモデルは、合成データやフィルタリングされた公開データなど、さまざまなデータでトレーニングされています。
MMDiT-X
Stable Diffusion 3.5 Medium は、画像品質、タイポグラフィ、複雑なプロンプトの理解、リソース効率の向上を特徴とする、改良された Multimodal Diffusion Transformer with improvements (MMDiT-X; マルチモーダル拡散トランスフォーマー)によるテキストから画像へのモデルです。
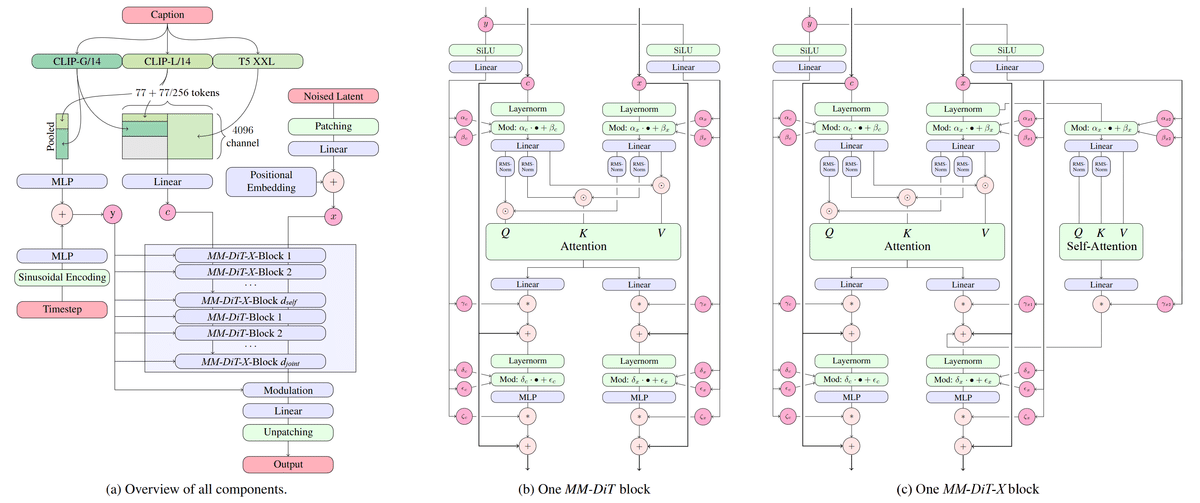
MMDiTのオリジナルアーキテクチャの技術的な詳細については、研究論文を参照してください。
使用法と制限事項
このモデルは長いプロンプトを処理できますが、T5トークンが256を超えると、生成の端にアーティファクトが発生することがあります。このモデルをワークフローで使用する際はトークン制限に注意し、アーティファクトが顕著になる場合はプロンプトを短くしてください。
中規模モデルは大規模モデルとは異なるトレーニングデータの分布であるため、同じプロンプトに対して同じように反応しない場合があります。
より良い構造と解剖学的整合性を得るために、Skip Layer Guidanceでサンプリングすることをお勧めします。
Skip Layer Guidance (SLG)の推奨
Stability AIが提案している方法としてはSkip Layer Guidance (SLG)です。Skip Connection(残差接続)についてはこちらの日本語解説が詳しいです。これによって指の改善がStability AIによって提案されており、ComfyUIやHuggingFaceでも試されています。
スキップ レイヤー ガイダンス (SLG) は、特定の範囲のサンプリング ステップで元の CFG に追加のガイダンスを追加するサンプリング手法です。追加のガイダンスは、元のモデルからの正の DiT モデル出力から、特定のレイヤー (たとえば、Stable Diffusion 3.5 Medium の場合はレイヤー 7、8、9) が削除されたバリアント モデルからの正のモデル出力を減算して比較することによって計算されます。
SLG はオプションの選択肢のように見えますが、SAI は Stable Diffusion 3.5 Medium に対して SLG を有効にすることを公式に推奨しているようです。証拠には以下が含まれます:HuggingFace Hub の公式リポジトリでは、 SLG が有効になっているComfyUI ワークフローが提供されています。
公式リファレンス デザイン GitHub リポジトリStability-AI/sd3.5には、SD3.5-medium の SLG をサポートする最近の変更が含まれています。
Stable Diffusion 3.5 Medium での SLG の使用について取り上げたReddit (例:こちら) および Twitter/X (例:こちら) の投稿では、SLG の使用は「解剖学的失敗の可能性を減らし、全体的な一貫性を高める」ために重要であると思われると示唆されており、複数の独立した投稿がこの主張を相互検証しています。
More examples of how SLG works with #SD35M
— Dango233 (@dango233max) October 29, 2024
So, the knowledge is all in the model - SLG extracts it.
Off / On (SLG scale = 1, dropping layer 7,8,9) https://t.co/SnHVJFdlRl pic.twitter.com/7jQaqGNOhS
HuggingFaceおいてワークフローが配布されています。
さいごに
今後も、Stable Diffusionを中心としたオープンな画像生成モデルとそのコミュニティの熱狂は続きそうです。
AICUとしては「つくる人をつくる」をビジョンにする専門AIメディアとして今後も、公平に、Stability AIやコミュニティの活動を応援していきたいと考えています。
いいなと思ったら応援しよう!
