

[ComfyMaster37] SDXL+AnimateDiff+IPAdapterで参照画像から動画を生成しよう! #ComfyUI

前回のAnimateDiffによるtext-to-video(t2v)での生成方法に興味を持った方は、さらに一歩進んだ動画生成を試してみませんか?
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第37回目になります。
本記事では、AnimateDiffにIPAdapterを組み合わせることで、ただのテキストからの動画生成を超え、画像の特徴を反映させたより一貫性のあるアニメーションを作成する方法を紹介します。特定のビジュアルテーマやキャラクターを保持したまま、ダイナミックな動画を生成できるこの手法は、クリエイティブなプロジェクトにおいて強力なツールになるはずです。IPAdapterを活用して、これまでにない精度と表現力を持つ動画制作に挑戦してみましょう!
[ComfyMaster36] 動画から新しい動画を生成しよう! #ComfyUI
1. 概要
本記事では、AnimateDiffとIP Adapterを組み合わせて、text-to-video(t2v)での動画生成を行う方法を解説します。IP Adapterは、画像の特徴を抽出して生成プロセスに反映させる機能を持ち、これにより元の画像を参照しながら、一貫性のあるアニメーションを作成できます。従来のt2vでの生成に対して、IPAdapterを使うことで、より具体的で視覚的なテーマに沿った動画を作ることが可能です。
このワークフローでは、複数のカスタムノードやモデルをインストールし、それらを適切に組み合わせて動画生成を行います。具体的には、RealVisXLやSDXL Motion Modelを使用してサンプリング効率を向上させ、CLIP Visionを通じて画像の特徴を抽出し、IP Adapterでそれらを動画生成に反映させます。
2. カスタムノードのインストール
以下のカスタムノードを使用するため、ComfyUI Managerからインストールしてください。
ComfyUI-AnimateDiff-Evolved
ComfyUI-AnimateDiff-Evolvedは、Stable Diffusionモデルを拡張して動画生成を可能にするカスタムノードです。元のAnimateDiffを進化させたバージョンで、動画生成のためのモーションモジュールと高度なサンプリング技術を組み込んでいます。
ComfyUI-VideoHelperSuite
ComfyUI-VideoHelperSuiteは、動画生成を支援するためのカスタムノードです。動画の編集や加工を容易にする機能を提供します。今回は、一連の画像を動画にして保存するノードを使用するために必要となります。
ComfyUI IPAdapter plus
ComfyUI IPAdapter Plusは、ComfyUI上でのIP Adapterの使用をサポートするカスタムノードで、画像をプロンプトとして使用する機能を提供します。キャラクター、スタイル、構図の転写や高度な一括処理が可能で、動画や漫画の生成時に一貫したビジュアルテーマを維持するために使用されます。
3. モデルのインストール
RealVisXL V5.0 Lightning
今回は、RealVisXLのLightningバージョンを使用します。Lightningバージョンでは、サンプリングのステップ数を4-6回に抑えることができます。生成量の多いAnimateDiffでは、TurboやLightningなどの数ステップで生成完了するモデルを選ぶと良いでしょう。
以下のリンクよりモデルをダウンロードし、「ComfyUI/models/checkpoints」フォルダに格納してください。
SDXL Motion Model
今回は、SDXLのモーションモジュールとして、「Hotshot-XL」を使用します。Hotshot-XLは、コンテクスト長が8フレームしかありませんが、AnimateDiff-SDXLより品質が良いためです。以下のモデルをダウンロードし、「ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/models」フォルダに格納してください。
CLIP Vision
IP Adapterを使用するためにCLIP Visionを使用します。以下のリンクよりモデルをダウンロードし、「ComfyUI/models/clip_vision」フォルダに格納してください。
CLIP Visionは画像を入力として受け取り、特徴を抽出してトークンに変換します。これらのトークンは、テキストプロンプトと組み合わせて画像生成に使用されます。
IP Adapter
CLIP Visionで抽出した画像の特徴を画像生成モデルに組み込むためにIP Adapterのモデルが必要になります。以下のリンクよりモデルをダウンロードし、「ComfyUI/models/ipadapter」フォルダに格納してください。
4. 使用素材
今回は、女性の画像と風景の画像を使用します。それぞれ以下よりダウンロードしてください。
女性の画像

girl_01.jpg(右クリックで保存)
風景の画像

landscape_01.jpeg(右クリックで保存)
5. ワークフローの解説
以下がワークフローの全体像になります。このワークフローは、入力画像の特徴を活かしながらアニメーション動画を生成する高度な例です。IP-Adapterを使用することで、入力画像の視覚的特徴(この場合、若い日本人女性の外見)を生成プロセスに組み込みます。AnimateDiffとの組み合わせにより、入力画像に基づいた一貫性のあるアニメーション動画が生成されます。
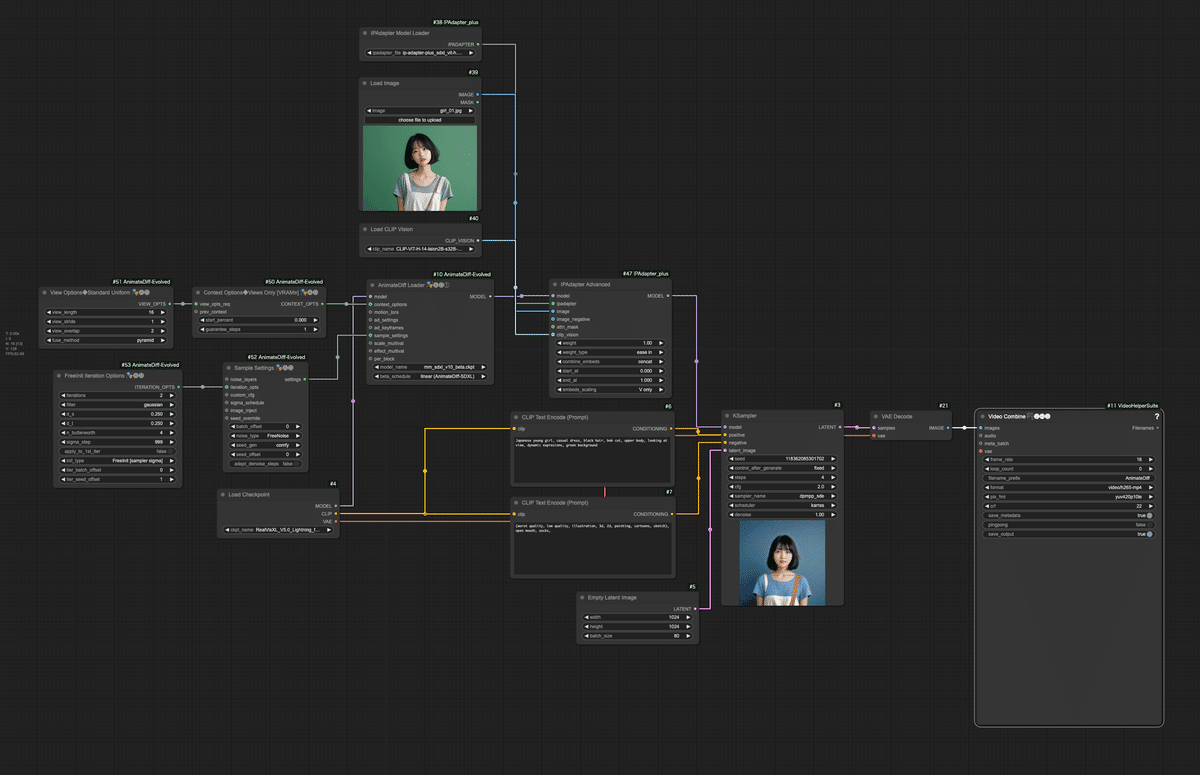
ワークフローは、文末のリンクよりダウンロード可能です。
このワークフローの構造をフローチャートで表現すると、以下のようになります。
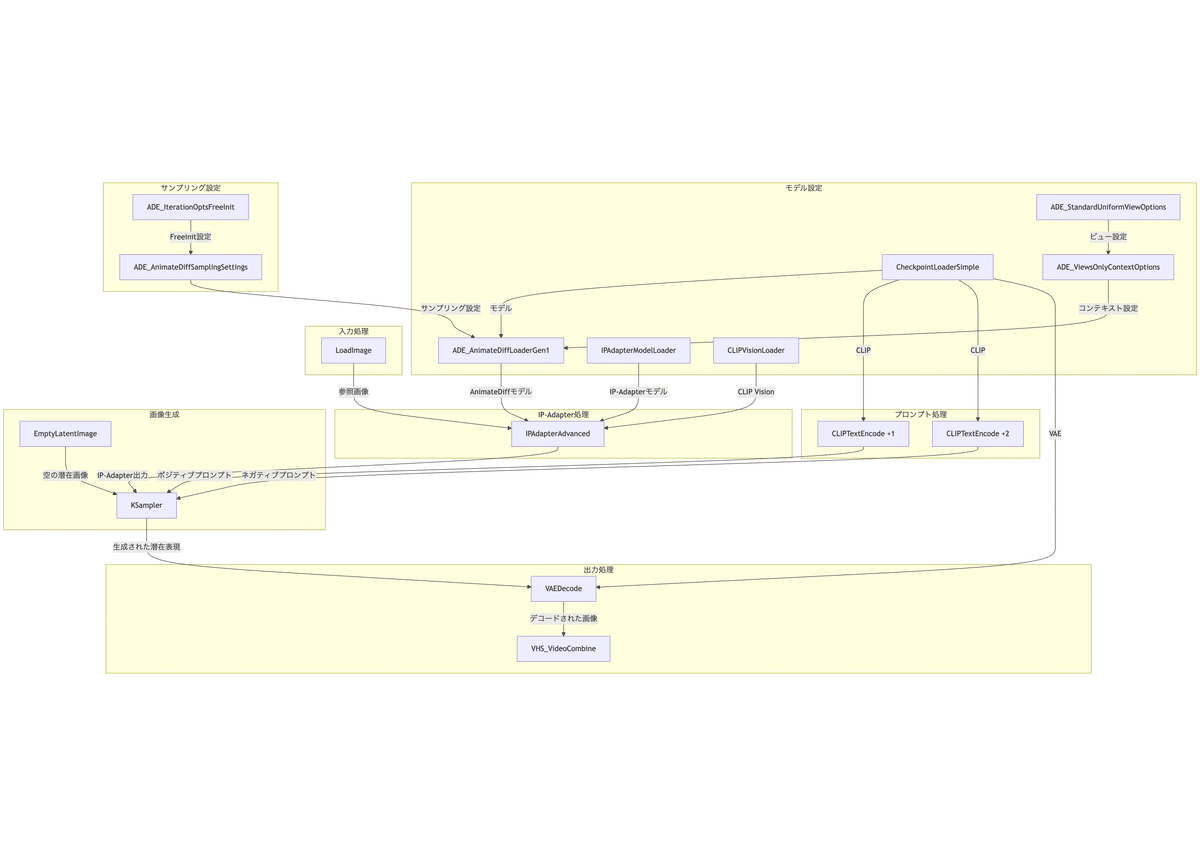
以下に、このワークフローの主要な部分とその機能を詳細に説明します。
入力画像とモデルの準備
Load Imageノード: 「girl_01.jpg」という画像ファイルを読み込みます。
IPAdapterModelLoader ノード: 「ip-adapter-plus_sdxl_vit-h.safetensors」モデルを読み込みます。
CLIPVisionLoader ノード: 「CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors」を読み込み、画像の特徴を抽出します。
CheckpointLoaderSimple ノード: 「RealVisXL_V5.0_Lightning_fp16.safetensors」モデルを読み込みます。
AnimateDiffの設定
ADE_AnimateDiffLoaderGen1 ノード: 「hsxl_temporal_layers.f16.safetensors」 AnimateDiffモデルを適用し、「autoselect」モードを使用します。
ADE_StandardUniformViewOptions ノード: AnimateDiffのビューオプションを設定します(16フレーム、2キーフレーム)。
ADE_ViewsOnlyContextOptions ノード: ビューオプションをコンテキストオプションに変換します。
サンプリング設定
FreeInit Iteration Optionsノード: FreeInit samplingのパラメータを設定します。イテレーション回数が多いほど、生成される動画の詳細度や一貫性が高まります。今回は、最低回数の2回だけイテレーション処理を行います。
Sample Settingsノード: AnimateDiffのサンプリング設定を構成します(FreeNoiseモード)。
IP-Adapter処理
IPAdapterAdvanced ノード: 入力画像の特徴を抽出し、生成プロセスに組み込みます。重み1.0、「ease in」ブレンドモード、「concat」適用方法を使用。
プロンプト処理
ポジティブプロンプト: 「Japanese young girl, casual dress, black hair, bob cut, upper body, looking at view, green background」
ネガティブプロンプト: 「(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth,」
画像生成
KSampler ノード
Seed: 118362085301702
Steps: 4
CFG Scale: 2.0
Sampler: dpmpp_sde
Scheduler: karras
Denoise: 1.0
出力処理
VAE Decode ノード: 生成された潜在表現を実際の画像にデコードします。
VHS_VideoCombine ノード: 生成された画像シーケンスを16fpsの動画に変換し、「AnimateDiff」というプレフィックスで保存します。
6. ワークフローの実行
それでは、ワークフローを実行してみましょう。女性の画像を参照した場合と、風景の画像を参照した場合、それぞれの結果を確認してみます。
女性の画像を参照しての動画生成
まずは、Load Imageノードに女性の画像を設定し、以下のプロンプトをポジティブプロンプトに入力し、実行してみます。
Japanese young girl, casual dress, black hair, bob cut, upper body, looking at view, dynamic expressions, green background
実行結果は以下になります。参照元画像の特徴を捉えて生成されていることが分かります。しかし、あくまで参照なので、参照元画像のままで生成されていません。また、参照により動きがあまり変化しない特徴があります。

IPAdapterの強度を下げれば、動きの変化が強くなりますが、その分参照元画像に似なくなります。以下は、IPAdapterの強度を0.5に下げて生成した動画です。

風景画像を参照しての動画生成
次に風景の画像を参照し、そこから動画生成したいと思います。Load Imageノードに風景の画像を設定し、以下のプロンプトをポジティブプロンプトに入力し、実行してみます。
wide landscape view, sunset, golden hour, large clouds, pink sky, ocean in background, water reflections, distant mountains, lush green trees, flowers in foreground, gentle breeze, glowing sunlight, ethereal atmosphere, serene, soft lighting, cinematic composition, high detail, vivid colors, dreamy, fantasy setting
以下が生成結果です。参照元画像に近い状態で動画生成されています。先ほどの女性と同様、参照元画像に引っ張られるため、動きは小さいです。

IPAdapterを使用しない場合は、以下のようにさらに躍動的な動画になります。

7. まとめ
今回の記事では、AnimateDiffとIPAdapterを組み合わせたtext-to-video生成の手法を解説しました。IPAdapterを活用することで、従来の動画生成におけるテキストプロンプトだけでなく、参照画像の特徴を反映した一貫性のあるアニメーション動画を作成することができます。これにより、キャラクターやスタイル、構図の再現が容易になり、より具体的で表現豊かな動画制作が可能になります。
記事内で紹介した手順を参考に、カスタムノードのインストールやモデルの準備を行い、IPAdapterの設定を適切に調整することで、プロジェクトに合わせた多彩なアニメーションを生成することができるでしょう。今回の手法は、特にクリエイティブな作品や映像制作において、大きな可能性を秘めています。
今後もこの技術を活用し、自分だけのユニークなアニメーション動画を作成してみてください。次のステップでは、さらに高度なカスタマイズや他のツールとの組み合わせを試して、より洗練された映像表現を目指していきましょう。
次回は、AnimateDiffでvideo-to-video(v2v)をする方法を紹介します。乞うご期待!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。メンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になるだけでなく、さまざまな交流情報や、ComfyUIを学習するためのメンバー向け情報をお伝えしています。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!