

「画像生成AI Stable Diffusion スタートガイド」アップデート情報 第6章 LoRA動作不具合改訂について #SD黄色本

2024年3月29日発刊した「画像生成AI Stable Diffusion スタートガイド」ですが、おかげさまで重版が決定し、それにあわせて内容の改訂を実施しています。
初稿以降の更新の中でも特に大きな修正すべき不具合として、第6章「LoRAを作って使ってみよう」で紹介していたLinaqruf版のKohya Trainerがメンテナンス終了→アーカイブとなり、うまく動作しない状況が続いていました。
AICU media編集部では、移行先として複数のLoRA Trainerを検討しています。
① Stability Matrixに収録されている「kohya_ss」
② Google Colab で動作するGUI版「Kohya_ss」
③ Lora Trainer by Hollowstrawberry
④ Linaqruf版をベースにAICUがメンテナンスしつづける
初学者に向けて安定した体験環境を維持するという要素と、旧来の書籍にありがちな最新のアップデートについていけなくなるという状態を避ける両方の意図から、今回は、③のHollowstrawberry版を使って「初心者に向けてローカルGPUを使わずにできるだけ短い設定でLoRAをつくる体験をする」を本書の公式サポート情報として提供いたします。
今回は学習時に要求されるVRAM(GPUのメモリ)と画像を生成した際のコントロールのしやすさを考慮し、1.5 モデル用の LoRA を制作します。
データセットを用意する
LoRA は何枚かの画像の特徴を学習することによって作られます。そのため、共通の要素を持った画像を複数枚用意することが必要です。この学習元の画像群のことを「データセット」と呼びます。
今回は絵全体の雰囲気を学習し、画風を再現した LoRA を制作するので、AICU のパートナークリエイターである「9食委員さんから許諾された15枚のイラストをデータセットとして使用します。
https://www.pixiv.net/users/59031070
画風を再現すると言っても、画風という言葉は具体的な特徴を指していないので、今回は目標通りの LoRA が制作できたかどうかを確認するために再現したい特徴をあらかじめピックアップしておきましょう。

注意:学習元画像に関して、日本の法律では他人が著作権を持つ画像を 「AIの学習に用いること」は可能ですが、その学習結果による「モデルやLoRAそのもの」や「LoRA を使って生成した画像」にはそれらの製作者が責任を持つ必要性が存在します。そのため、「他人が創作した画像」を無許可で学習対象として使用することや出処不明の画像を使用し、インターネット等に公開したり流通させることは個人であっても著作権侵害、商標権侵害として罰される可能性があります。また商用利用する場合はライセンスの解決が必要であり、レピューテーション(reputation;風評被害)などの責任を負う可能性があるため、SD黄色本では「推奨しない行為」としています。またフリー素材サイト等から画像をダウンロードして使用する際も、必ず利用規約を読み、学習・生成・商用利用・再配布などの問題が無いことを確認し、理解してから使用しましょう。
そのためAICU media編集部ではトレーニング用のデータセットを用意してあります。SD黄色本の読者は問題なく実験をすることができます。
データセットの解像度と正規化
学習させるデータの整理についても解説しておきます。今回行う LoRA の学習はSD1.5系のため、解像度としては 512×512 px が最適になります。SDXL系の場合は 1024×1024 px の画像を学習するため、あらかじめ画像のサイズを調整しておく必要があります。Photoshop などの画像エディタで 1024×1024px にトリミング、縮小または不足部分は塗り足ししておきます。このようにデータを一定ルールに合わせて整理することを正規化と呼びます。また今回は学習画像を増やすために、画像を複製し左右反転したものも追加し、30枚に増やしました。
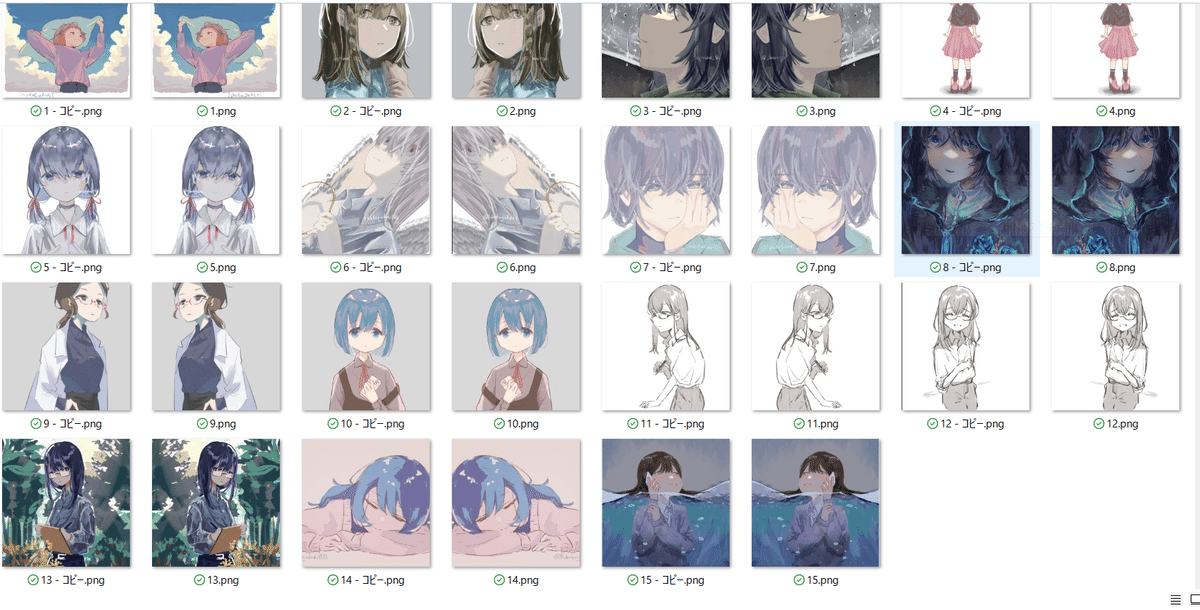
一般的にLoRAによる作風の学習をする際は、30枚〜50枚の画像を学習させると品質を安定させられるといわれています(新技術もあり諸説あります)。枚数が不足する場合はトリミングしたり、鏡像を作るなどして増やすことも有効です。また学習する画像に作者の都合で偏りがある場合もあります。たとえば「左向きの顔が多い」など、生成するLoRAに反映させたくない偏りが生じていると、それも特徴の1つとして学習されてしまうことがあります。その場合は左右反転したコピーを追加しておくことが有効です。
サンプルデータセットの入手方法については後ほど紹介します。
Google Colaboratoryを使ったLoRA生成
データセットの準備が整ったらGoogle Colaboratory を用いてLoRA学習を行っていきましょう。
アップロードができたら、以下のColab notebook を開きます。
AICU版 Lora Trainer by Hollowstrawberry
これは 日本人の開発者 kohya-ss さんが開発制作した「sd-scripts」を Linaqruf さんが Colab notebook で使用できるようにしたDreambooth形式と呼ばれるLoRA学習スクリプトです。さらにそれをHollowstrawberryさんがデータセット準備ツールと学習部分を切り分けてシンプルにしてメンテナンスしているスクリプトで、オープンソースの賜物ともいえます。「j.aicu.ai/SDLoRA2」は、それを AICU media編集部が日本語訳と操作方法の説明を追記し、SD黄色本の第2版に準備したものです(不具合や分かりづらい所があればレポート歓迎です)。
Colabノートブックの起動
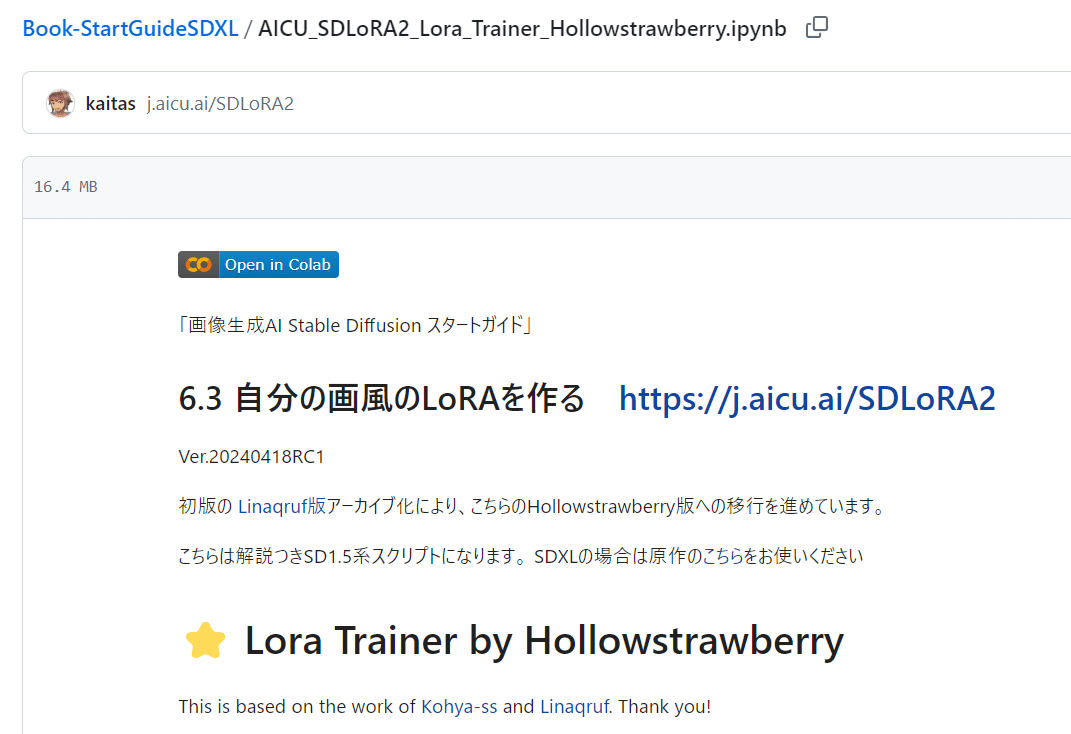
まず Colab に接続します。「Open in Colab」ボタンを押し、次に「ドライブにコピー」ボタンを押して、自身のGoogle Driveに保存します。
本書では A1111 WebUIを使用する際は 「T4 GPU」 に接続していますが、時間に余裕がある方は同様に「T4 GPU」で問題ありません。より高速な処理を希望される方は『ランタイム』→『ランタイムのタイプを変更』をクリックして選択し、『A100 GPU』を選択しましょう。
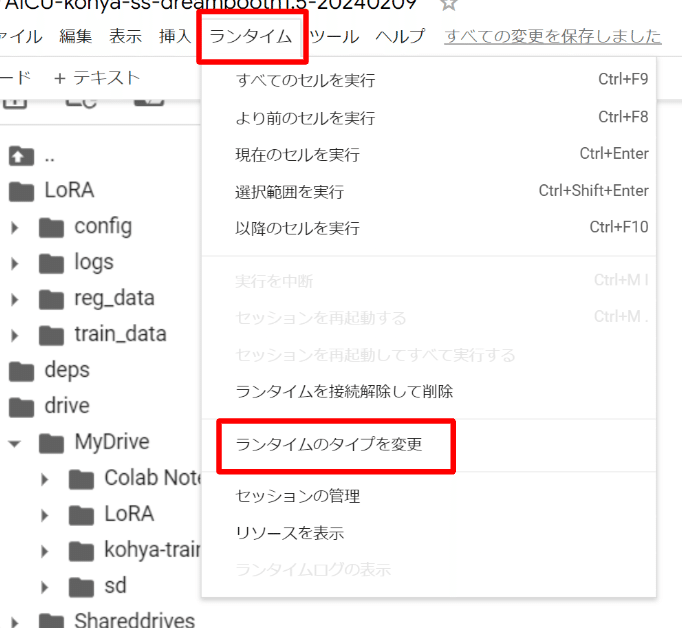
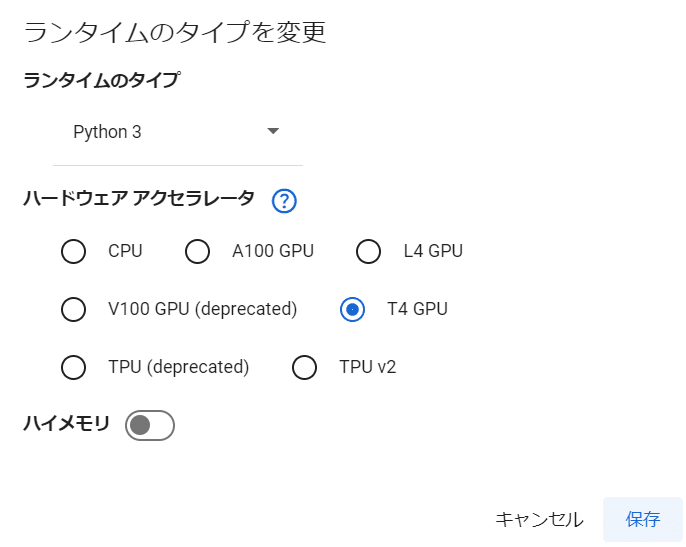
なお、最近のGoogle Colabのアナウンスにより、「V100」と「TPU」は終了宣言され、その代わりに 「L4 GPU」が登場しています。
学習データセットのダウンロード
接続が完了したらまず、データセットのダウンロードと展開を行います。
サンプルデータが必要な方は AICUの HuggingFaceへどうぞ
https://huggingface.co/AICU/SDXL-LoRA/tree/main
ZIPファイルはこちらのURLになります
https://huggingface.co/AICU/SDXL-LoRA/resolve/main/9shoku0219.zip
お使いの Google Driveに接続し、マイドライブのトップ「Loras」フォルダに自動でAICU media編集部が用意したサンプルデータセットをダウンロードし、展開する処理を用意してありますので実行していきます。
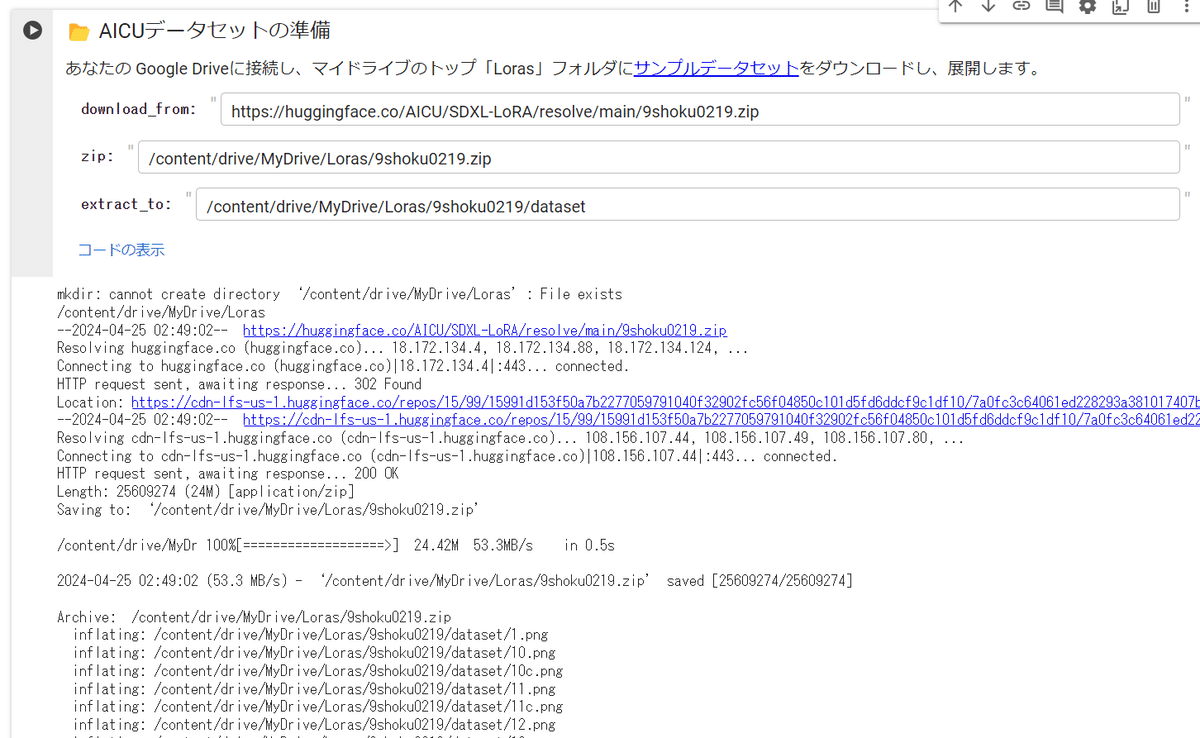
このセルの ▶ボタンを押すだけで、zipファイルをマイドライブの「Loras」フォルダにダウンロードし、「9shoku0219/dataset」にフラットに展開する設定になっています。
ご自身のデータを使う場合は、プロジェクト名を「9shoku0219」の代わりに命名し、Google Drive内でフォルダを作成し、その下に「dataset」というフォルダを作り、正規化した画像ファイルを配置してください。
このとき、この以下のウィンドウが表示される場合があります。
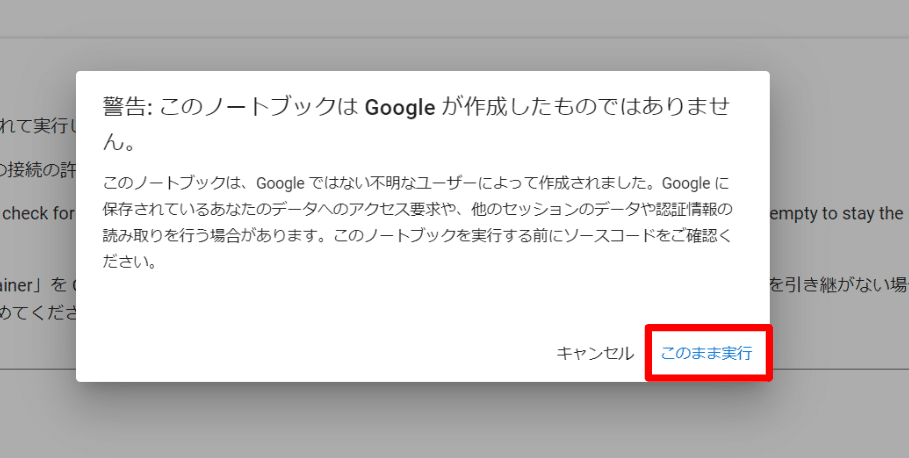
これは Google が作成していない notebook を実行する時などに表示されるものなので、『このまま実行』を選択します。今回はサンプルから変更する箇所が無いので問題ありませんが、独自データの学習など細かな設定を変更して何度も実験したい方は「ドライブにコピー」してから自分のノートブックとして保存してから開始するとよいでしょう。
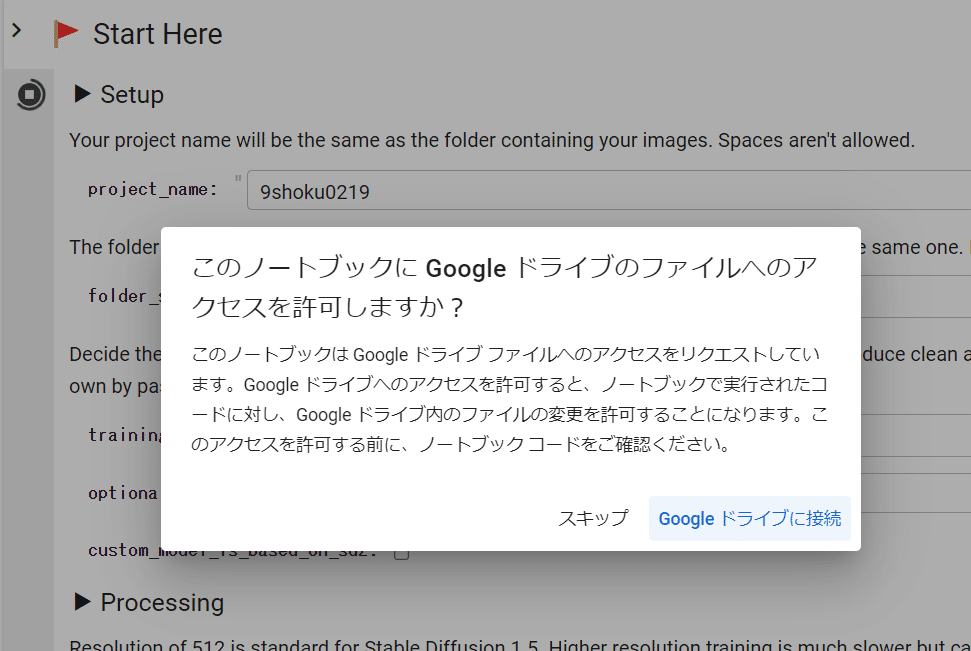
『Google ドライブに接続』を選択し、その後表示されるアカウントへの接続の確認を進め、アクセスを許可します。
学習前の設定確認
次に『Start Here』のセル内の項目を確認してから実行します。特に変更点はありませんが以下に解説します。
・「project_name」は今回のサンプルに合わせて「9shoku0219」になっており、前述の手順でアップロードを行っている前提ですが、変更する場合はスペースを含めないユニークな名前をつけてください。
・「folder_structure」はフォルダ構造でデフォルトは「MyDrive/Loras/project_name/dataset」になっています。学習元ZIPファイルは「MyDrive/Loras」に配置しています。
・「training_model」は、今回はイラスト画風を学習させますので「AnyLoRA (AnyLoRA_noVae_fp16-pruned/ckpt)」を選択します。写真系の画像など汎用の画像学習をする場合は Stable Diffusion を選択するとよいでしょう。

学習の開始
上記の設定を変更し、「Start Here」の左にある再生ボタンを押すと学習開始です。
ドライブへのアクセスを求めるウィンドウが開きます。
T4 GPUの場合は15分ほどで10エポック(世代)の学習処理が終了します。A100 GPUの場合2~3分で終わりますので、お急ぎの方は選択肢として知っておくとよいでしょう。
学習パラメータ
学習処理を実行している間にパラメータについても学んでおきましょう。
・resolution:今回はSD1.5系を利用しているので解像度は512x512ピクセルがStable Diffusion 1.5の標準です。解像度が高いほどトレーニングに時間がかかりますが、より良いディテールを得ることができます。ここでは「512」に設定しており、最適な結果が得られるようにトレーニング中に自動的に拡大縮小されるので、自分でトリミングやリサイズをする必要はありません。
・num_repeats:トレーニング中、画像はこの回数を繰り返し学習します。推奨回数は回数は200回から400回ですがこのサンプルでは10回としています。
・how_many:どのくらいの世代でトレーニングするかを選択します。10エポック(世代)または2000ステップくらいから始めるのがよいとされています。10エポック学習する設定になっており、1エポックは、画像数×繰り返し数÷バッチサイズです。今回のサンプルでは30枚の画像を10回繰り返し、バッチ数は150、指定エポックまでのステップ数は1500と計算されています。1ステップごとsafetensorsファイルとして学習結果を保存します。

続いて重要な「学習率」という機械学習の専門用語についても解説しておきます。
学習率 (Learning rate;LR)とは、機械学習や統計学における最適化アルゴリズムにおけるチューニングパラメータのひとつです。「正解値」と、モデルから出力された「予測値」とのズレの大きさである損失関数を最小値に向かって移動しながら、各反復におけるステップサイズを決定していきます。大きな値を設定すると粗い学習は進みますが、目標とするゴールには辿り着けない可能性があります。画像認識のような「正解が必ずある」タスクと異なり、画像生成AIのモデルがゴールとする状態はなんなのか?は非常に難しく、自らの画風の探究と求める品質、かける時間とのバランスにもなりますので適切な値を設定する必要があります。
このサンプルのデフォルト値の場合「unet_lr:5e-4」「text_ecorder_lr:1e-4」という形で記載されています。「5e-4」は「5.0 × 10 の -4乗」つまり「0.0005」、「1e-4」は「0.0001」のことで、「2,000枚や10,000枚の中に、与えたサンプルを確率的に混ぜる」という意味になります。これらの値を仮に「1.0」とすると、「全サンプルが教師画像」という意味になります。学校の教室で例えるなら、そのクラスにいる学習者は「教師と全く同じ画像を数千回学ぶ」という命令をすることになります。これは「過学習」という状態で、多様な画像を学ぶことにはなりませんし、結果的に学習効率は下がってしまいます。
ある程度一般的な画像の中に教師画像を入れることで効率よく学習させるテクニックがあります。これを「汎化性能」といい、より柔軟で多様性のある画像が生成できるようになります。まず「与えた画像を全く学習していない」という状態であれば、この値を「1.0」に近づけていきます。逆に「元の画像にそっくりな画像ばかり生成される」という状態であれば、まずはU-Netに「1e-2」「1e-3」「1e-4」「1e-5」というより小さな数字にすることで汎化性能を上げていくことができます。コピー機のようなLoRAから、より多様な画像が生成できるLoRAになっていくはずです。画像を生成するunet_lrに対してtext_encoder_lr、つまりテキストエンコーダはその値を0.5倍、つまり半分にしています。
大きな値を設定すると、トレーニングには数分から数時間、数日といった規模になります。Google ColabもPro以上のライセンスと高火力なGPUを利用するコンピューティングユニットが必要になります。初心者にむけてそのような難度が高い機械学習タスクを設定することは適切ではないので、このサンプルの場合は小規模の数字で結果が出るように調整しています。また機械学習やその調教には正答がはっきりあるわけではありません。セオリーとしてはColabのテキスト欄や学習計画を管理して、(運や感覚ではなく)仮説検証型で試していくのがおすすめです。そうすれば有限回の試行で目的のLoRAを獲得できるはずです。
学習の完了とsafetensorsファイルの入手
epochが 10/10になれば学習完了です。
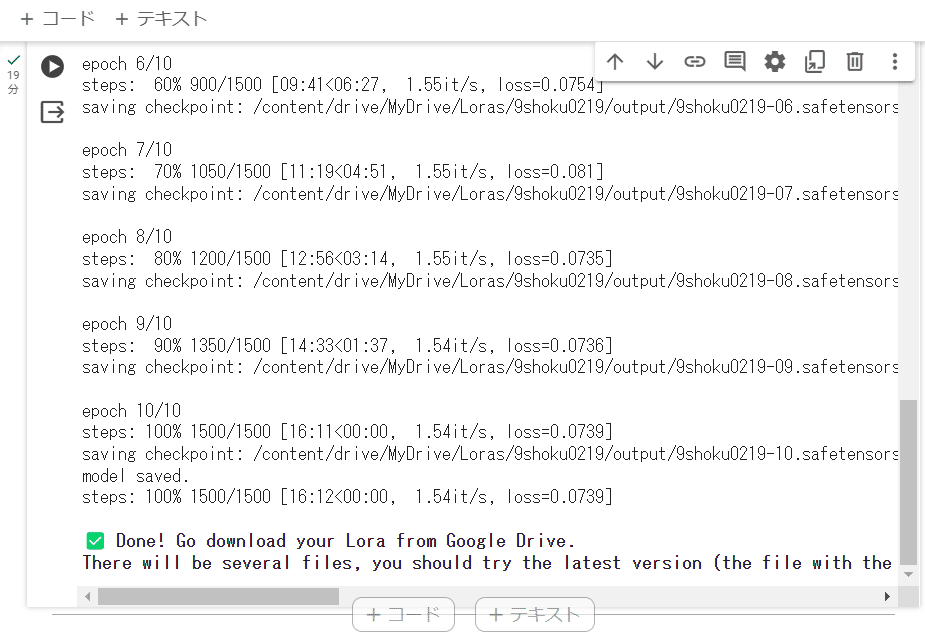
「完了!グーグルドライブからLoraをダウンロードします。 いくつかのファイルがありますが、最新版を試してみてください」と英語で表示されています。
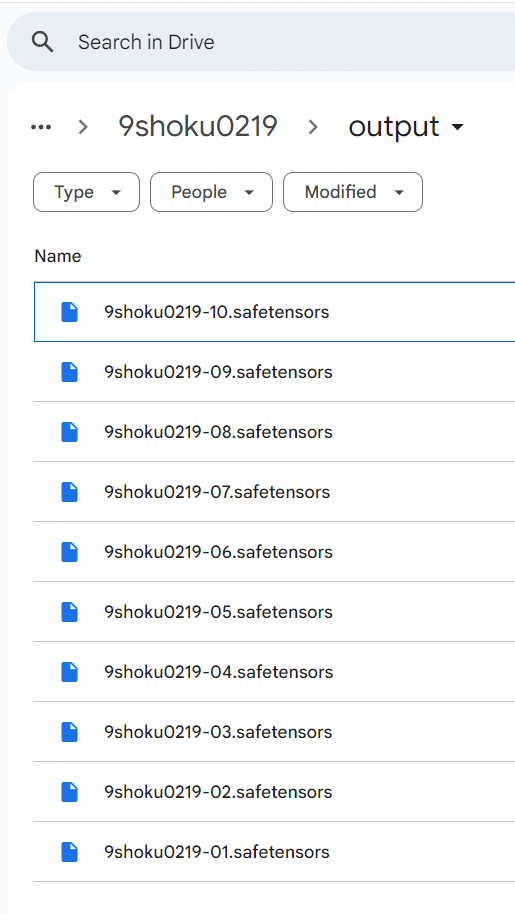
Google Driveのタブで、MyDrive/Loras/9shoku0219/output に移動すると以下のように、01~10の .safetensors ファイルが生成されているはずです。数字は学習世代を表しており、最新の「9shoku0219-10.safetensors」をA1111をお使いの環境にダウンロードして試用します。
AUTOMATIC1111での動作確認
次に生成した safetensorsファイルの試験になります。お使いの A1111 環境に戻ります。Stability Matrixのローカル環境か、Google Colab「http://j.aicu.ai/AnyLoRA」の環境を使ってみてください。このノートブックの http://j.aicu.ai/SBXL2 との差分は、起動前に今回のLoRA学習に使用したモデル「AnyLoRA」をダウンロードする設定がデフォルトになっている点です。
以下は、「j.aicu.ai/SBXL2」を使ったGoogle Colab環境での解説です。今回の作例ではアニメ系、イラスト系の画像を学習するかつSD1.5 系のモデル「AnyLoRA」を使用しているので Model Version で「1.5」を選択し、MODEL_LINK に以下のURLを設定します。
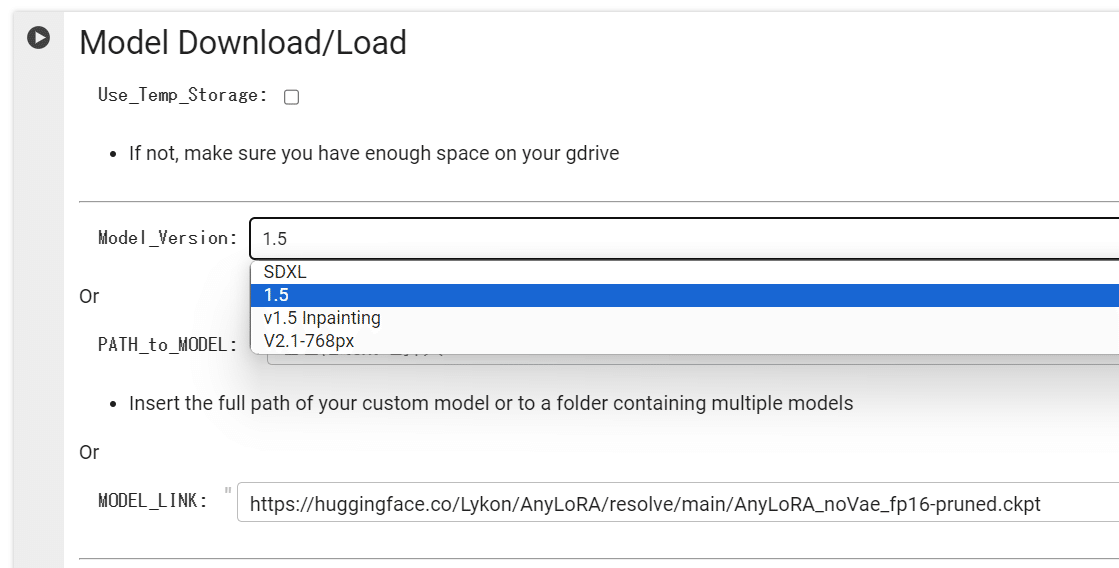
AnyLoRA
https://huggingface.co/Lykon/AnyLoRA
学習に使われているチェックポイントはこちらですが、VAEがないので画像が曇った感じの絵になる傾向があります。
https://huggingface.co/Lykon/AnyLoRA/resolve/main/AnyLoRA_noVae_fp16-pruned.ckpt
生成にはVAE込みのモデルを使ったほうが良いように思います。
MODEL LINK
https://huggingface.co/Lykon/AnyLoRA/resolve/main/AnyLoRA_bakedVae_fp16_NOTpruned.safetensors
これらのURLは Hugging Faceのダウンロードリンクを右クリックすると獲得できます。
safetensorsファイルの配置と確認
Stability Matrixの方は、ダウンロードした AnyLoRA(ファイル:AnyLoRA_noVae_fp16-pruned.ckpt)を Data/Models/StableDiffusion フォルダに配置します。
Google Colab環境で上記のスクリプト( http://j.aicu.ai/SBXL2 での追加ダウンロードもしくは http://j.aicu.ai/SBXL3 )を実行した場合、Google Driveの「sd」フォルダの下にA1111が展開されています。
Google Drive上で確認し、AnyLoRAが存在することを確認しておきます。
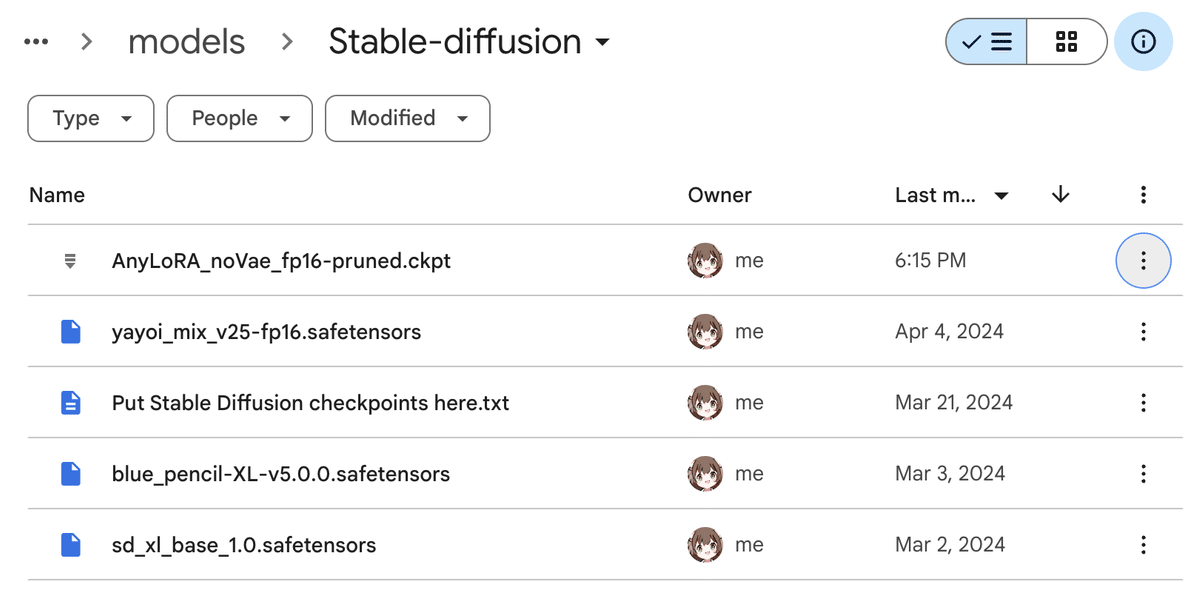
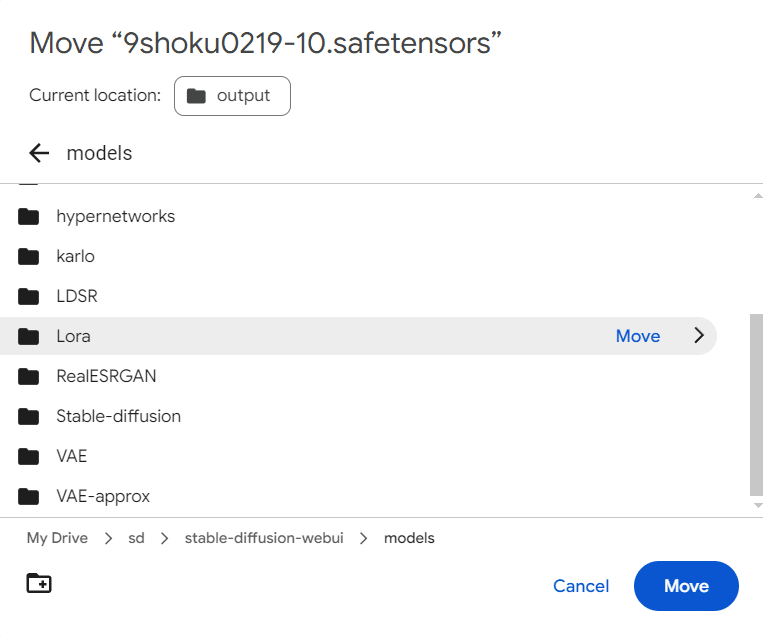
つづいて、生成したLoRAファイルを配置します。
Stability Matrixの方は、先ほどの最終段階でダウンロードしたファイル( 9shoku0219-10.safetensors)を Data/Models/Lora フォルダに配置します。
Google Colabの場合は
/content/gdrive/MyDrive/sd/stable-diffusion-webui/models/Lora
というパスになります。
Google Drive上で右クリックして、ファイルを移動させるとダウンロードする必要がありません。
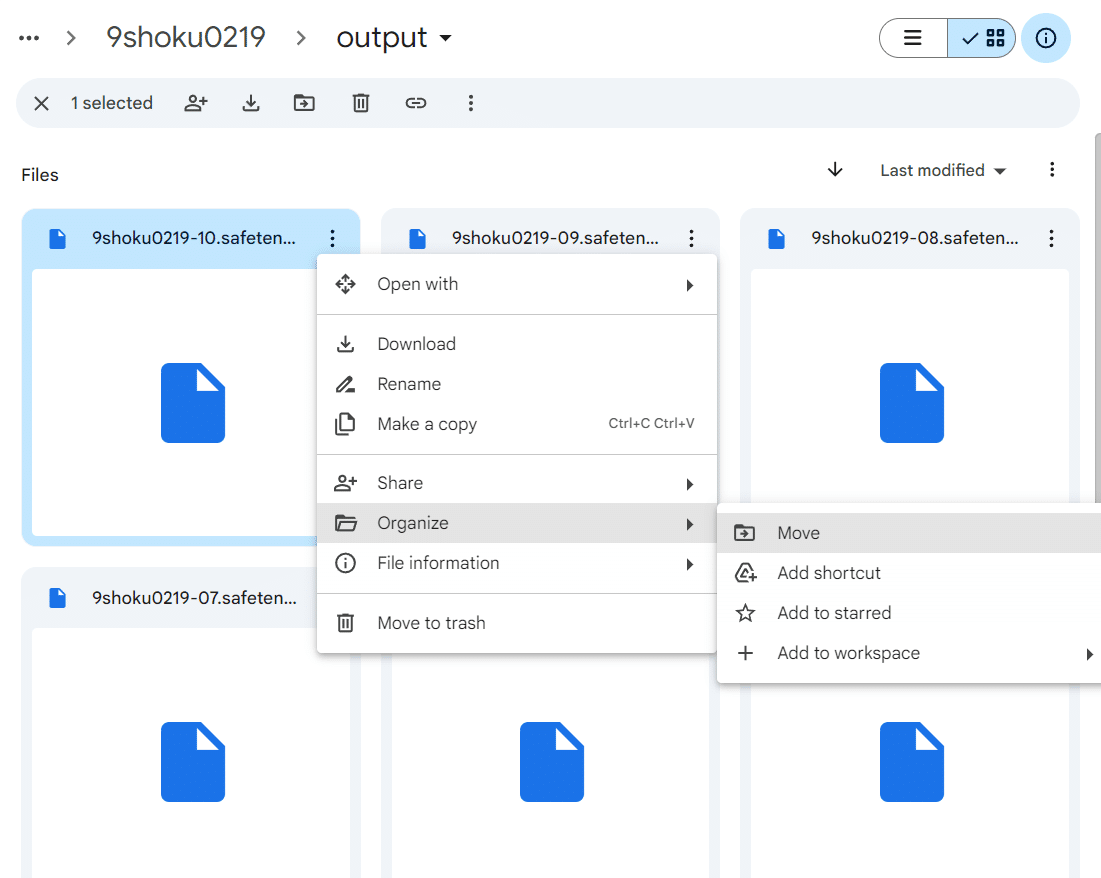
LoRAの動作確認
あとはこれまで通り、LoRAとしての利用をするだけになります。
A1111を起動し、左上の使用モデルに「AnyLoRA」が選ばれていることを確認したら、中央の「Generation」タブを「LoRA」に切り替えてみます。
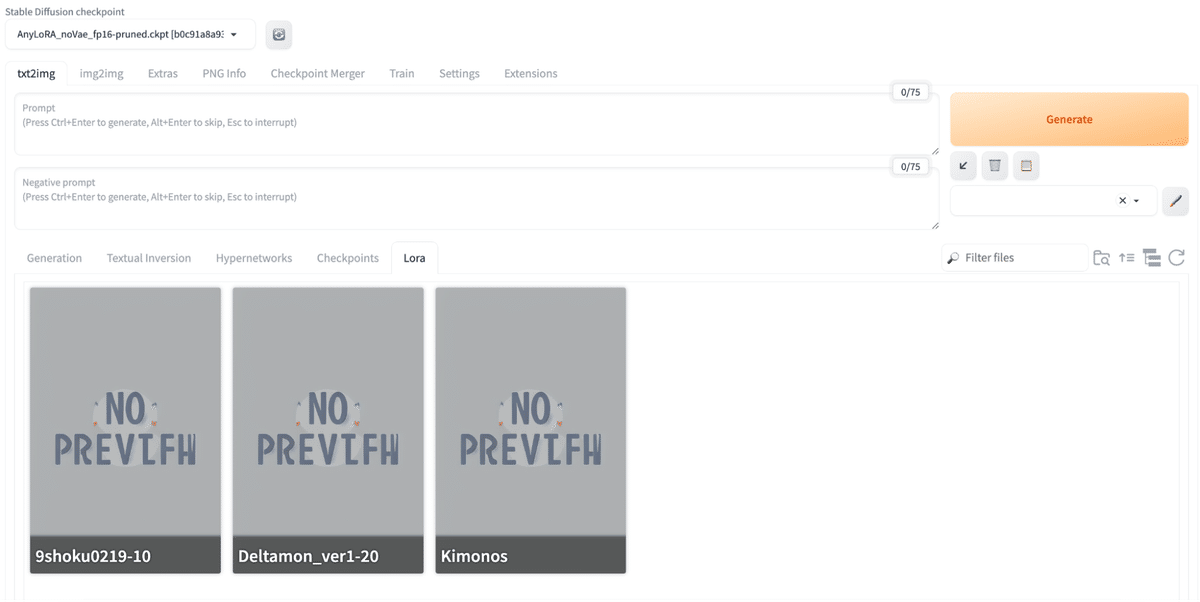
LoRAの詳細を見ると「9shoku0219」というOutput nameで学習されていることがわかります。
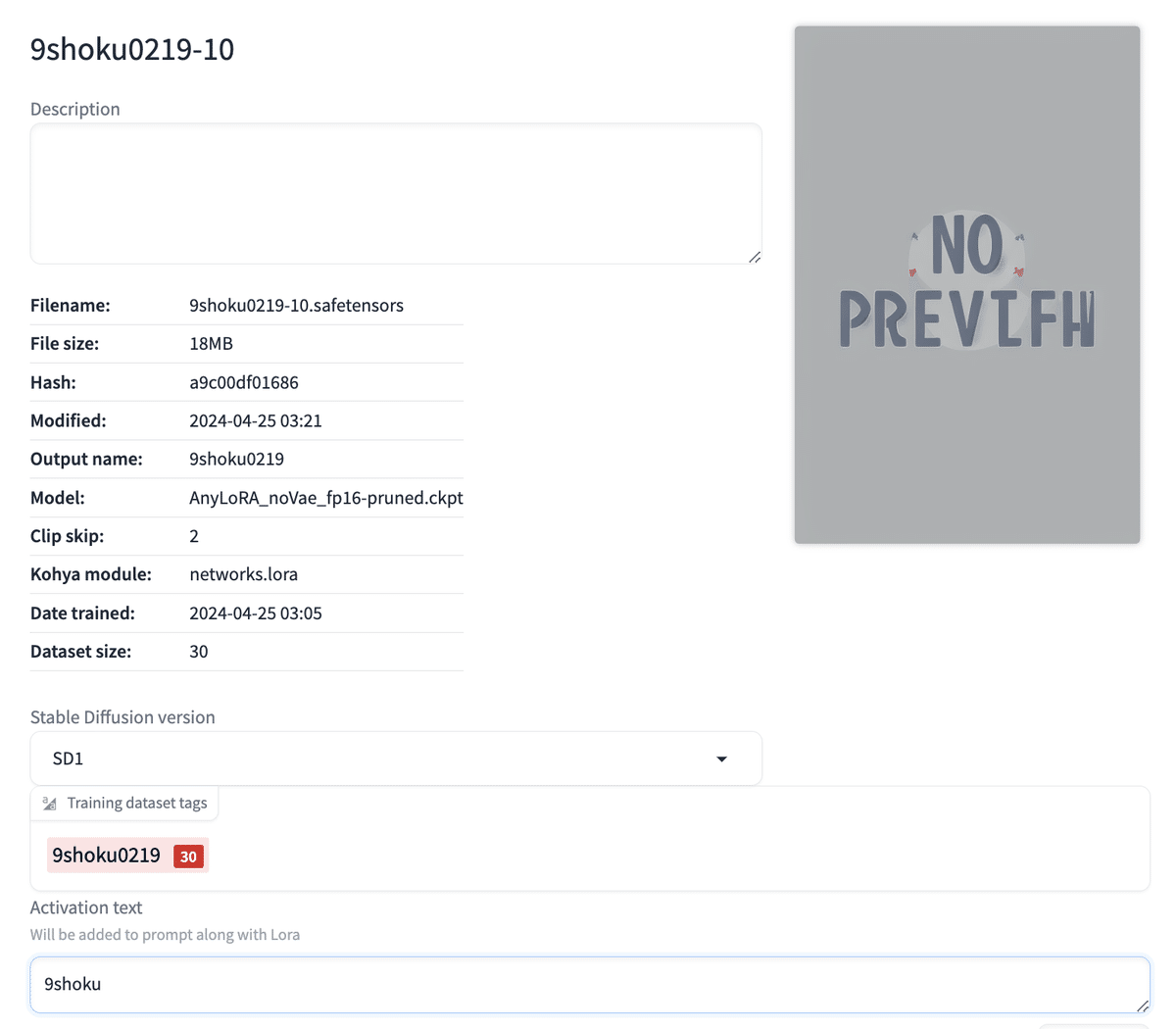
プロンプトを一度クリックし、LoRA(この場合は9shoku0219-10)をクリックし、LoRAタグを貼り付けます。例えばこんな感じのプロンプトになります。
1girl <lora:9shoku0219:1>
ネガティブプロンプトに「worst_quality」を加えて生成してみます。
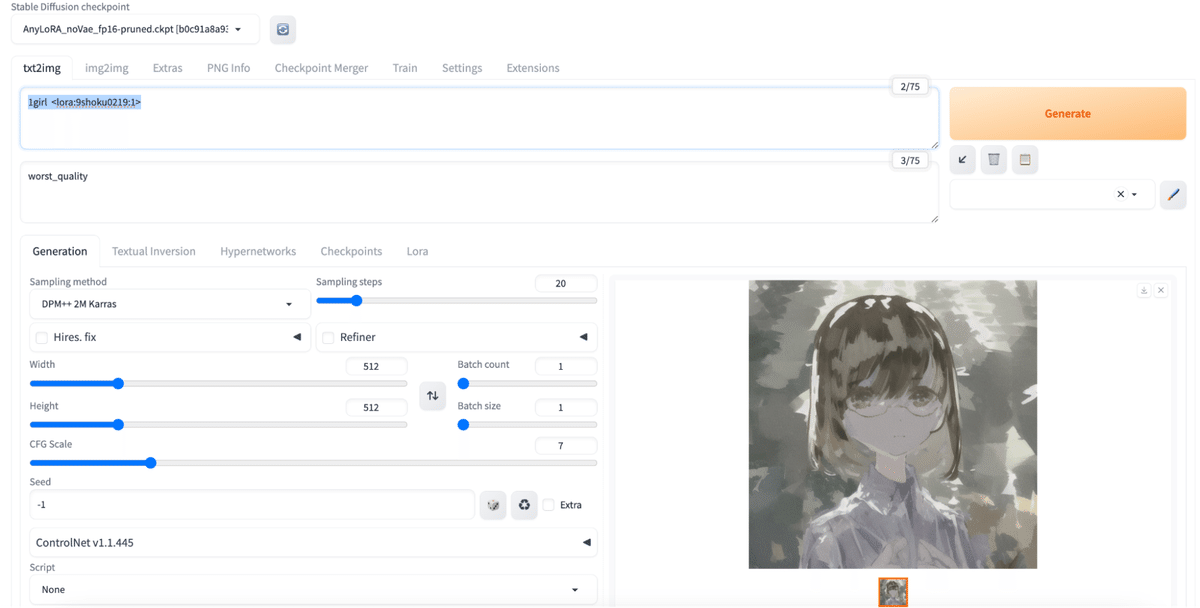
こんな感じで9食委員さん特有のダウナー少女が生成できればまずは成功です。

出力例


設定項目が少なかったわりに、なかなかいい感じではないでしょうか。
このあと目的に沿ってチューニングをかけていきます。
みなさんのいろんなLoRA習作を #SD黄色本 でお寄せください!
以上、Google Colabでつくる初心者向けLoRA最短設定でした。
本書でのLoRA関係は好評なので、今後も改訂を開発していきたいと考えております。フィードバックは本書のサポートメンバーシップおよびDiscordサーバーをどうぞ(書籍のp.63に記載されています!)
https://note.com/aicu/membership/boards
イベント告知
「この記事でもわからない…」というアナタ!
こちらのイベントもおすすめです
2024/05/15(水)19:00 〜 20:30 オンライン開催
【Stable Diffusion でデルタもん LoRA を作ろう!】「画像生成AI Stable Diffusion スタートガイド」 #SD黄色本 公式ワークショップ
https://techplay.jp/event/942272
有料イベントですが、その価値はあると思います!
オンラインサイン本販売もあるのでお早めの参加登録をおすすめします~!
いいなと思ったら応援しよう!
