

[ComfyMaster13]ComfyUIでのTextToImageを極める!!(3)Concatで複数CLIPをつなぐ

ComfyUIで「思い通りの画像を生成したい!けど思うようにいかない…」という方、TextToImage(t2i)を使いこなせていますか?
Stable Diffusionの内部の仕組みを理解し、ComfyUIでのText to Imageテクニックを身につけて、思い通りの画像を生成できるようになりましょう!
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第13回目になります。
前回は「ComfyUIでのTextToImageを極める!!(2)Combineでプロンプト融合」と題して複数プロンプトを組み合わせての生成について解説いたしました。
今回は、長文プロンプトを分割して意図した絵を生成する方法を解説いたします。
前回「ComfyUIでのTextToImageを極める!!(2)Combineでのプロンプト融合」はこちら。
前回は複数CLIPの活用として「Combine」を学びました。ComfyUIでは、複数のCLIPTextEncodeノードとConditioning(Combine)ノードを組み合わせることで、複数のプロンプトを同時に使用できます。例えば「龍」と「虎」を別々のCLIPTextEncodeノードに指定すると、「龍」と「虎」を組み合わせた画像を生成することができるようになりました。
でも今回のカバーアートのような「複数の人物を一つの画像で描くためには?」…?今回はConcat機能と複数CLIPを使って「プロンプトの限界」を超えていきます。
CLIPの内部と「Concat」
まず、自然言語処理やStable Diffusionにおける「トークン」とは、プロンプトに入力する単語や文字列といった「テキストデータを処理する際に使用される基本的な単位」を指します。1単語を1トークンとしてカウントし、区切りに使われるカンマ(,)も1トークンとみなされます。
モデルにもよりますが、SDXLの場合は75トークン(≒単語数)が1つの処理単位(バッチ)であり、75トークンを超える長いプロンプトの場合は、プロンプトを複数のバッチに分割して処理する方法が推奨されます。
長いプロンプトをChatGPTで作ってみる
例えば、 "A beautiful garden with red roses and white lilies blooming under a clear blue sky" というプロンプトがあるとします。


例えばChatGPTを使って「もっと詳細を!」と作文してもらいました。
プロンプトとしてはこんな感じです。
extract this stable diffusion prompt longer to 75 tokens.
"A beautiful garden with red roses and white lilies blooming under a clear blue sky"
make more detail for each words.
(このStable Diffusionのプロンプトを75トークンに長く引き延ばします。
「澄み切った青空の下、赤いバラと白いユリが咲き誇る美しい庭」
それぞれの単語をより詳しく説明)
A stunning, vibrant garden filled with deep red roses, their petals velvety and rich, alongside pristine white lilies, their petals delicate and gracefully open, all flourishing under a vast, clear blue sky with soft clouds gently drifting in the distance.
(深紅のバラが咲き誇る見事な庭園。その花びらはビロードのように滑らかで、濃厚な色合いです。その傍らには、花びらが繊細で優雅に開く純白のユリが咲いています。すべては広大な澄み切った青空の下で、遠くには柔らかな雲が静かに漂いながら、咲き誇っています)

更に拡大していきます。「more」といえば、ChatGPTがどんどん作ってくれます。
"A breathtaking, lush garden teeming with radiant, deep crimson roses, each petal exquisitely velvety and glowing under the sunlight. The roses stand tall and proud, surrounded by elegant, snow-white lilies with intricate, soft petals that curve gracefully outward. The lilies' golden stamens catch the light, contrasting with their pure white petals. The garden is bathed in warm sunlight, the vibrant greenery of the foliage complementing the vivid flowers. Above, the expansive sky is a brilliant, azure blue, with delicate wisps of clouds painted across the horizon, creating a serene and peaceful atmosphere, where every bloom flourishes in perfect harmony with nature."
「息をのむほど見事な緑豊かな庭には、鮮やかな深紅のバラが咲き乱れ、その花びらは、日光に照らされて、どれもこれも見事にベルベットのように艶やかです。バラは堂々と誇らしげに咲き、その周りには、複雑に入り組んだ柔らかな花びらが優雅に外側へと反り返る、エレガントな純白のユリが咲いています。ユリの黄金色の雄しべは光を浴びて輝き、純白の花びらとコントラストを描いています。庭は温かい日差しに包まれ、鮮やかな花を引き立てる葉の生き生きとした緑色が映えています。頭上には広々とした空が鮮やかな紺碧色に輝き、水平線には繊細な雲の塊が描かれ、静かで穏やかな雰囲気を醸し出しています。そこでは、あらゆる花が自然と完璧な調和を保ちながら咲き誇っています。」

ここまで来ると美しさも素晴らしいのですが、ワードカウントすると101ワードありました。
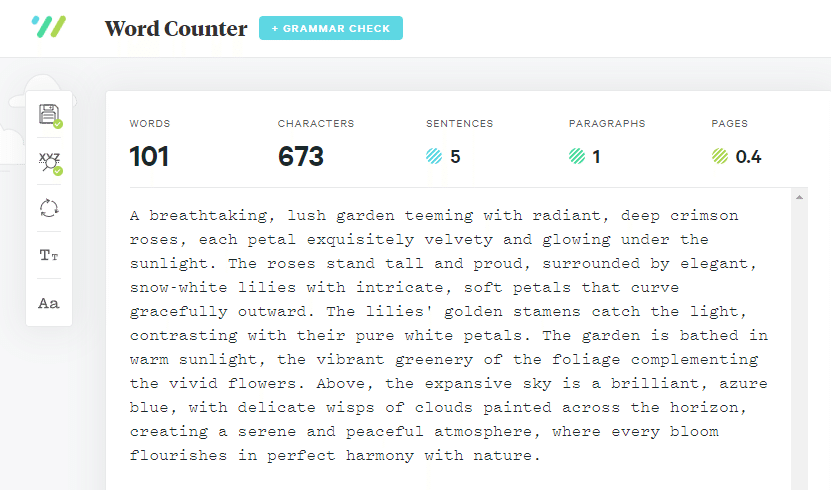
Tokenizerによるトークンの理解
トークン数についても数えていきましょう。CLIPは実はOpenAIによって開発された技術です。2021年1月5日にOpenAIによって公開された「言語と画像のマルチモーダルモデル」で、インターネットから集めた画像とテキストの40億ペアからなるデータになっています(最新のStable DiffusionではOpenCLIPなど違うCLIPが使われています)。
トークン化をカウントできるツール「Tokenizer」がOpenAIによって公開されています。
https://platform.openai.com/tokenizer
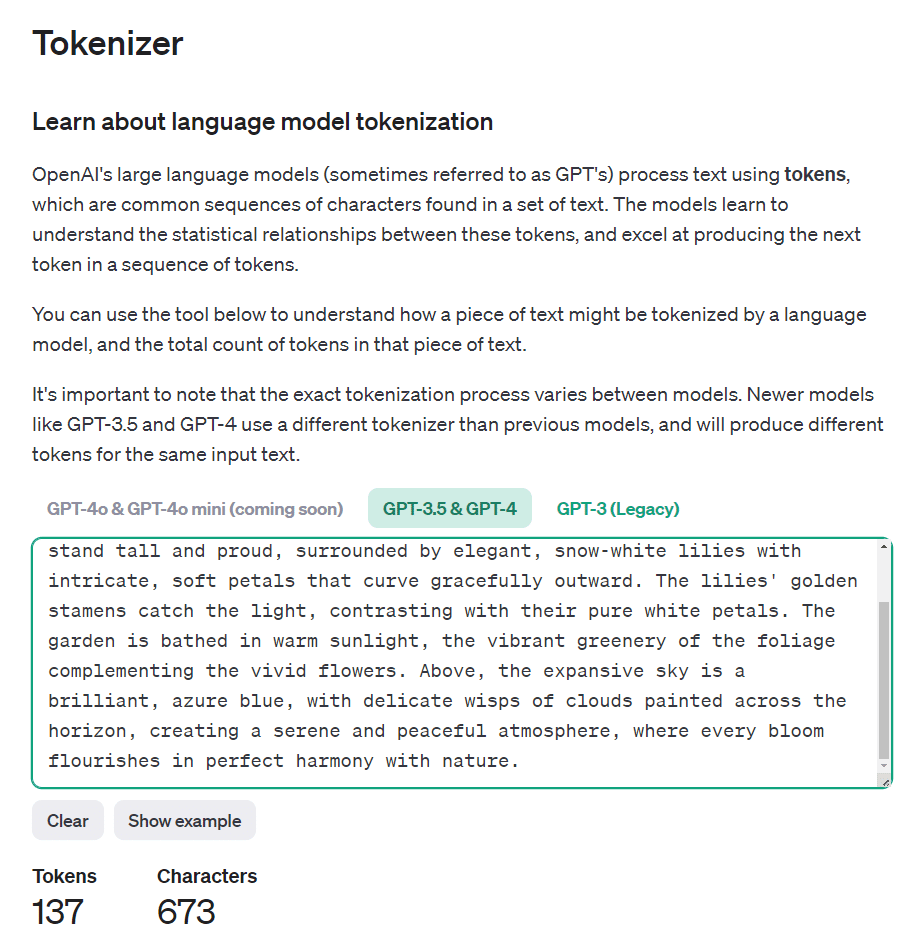
ワード数は101ワードでしたが、トークン数は137です。

[Token IDs]ボタンを押すと、トークンのIDを見ることができます。

Claudeを使ったComfyUIソースコードの理解
トークン数が75トークン超の場合、一般的に言われている仕様は以下のようなものです。
現在のバッチに入りきるだけの単語を追加します。
残りの単語は新しいバッチの先頭に追加します。
「誰かが言っている」という理解ではなく、実際のソースコードを分析してみる習慣をつけましょう。
ComfyUIのsd1_clip.pyの処理をClaudeに解説してもらいました。
このコードではトークンの最小値と最大値が設定されています。SD1Tokenizer クラスを詳しく見てみましょう
SD1Tokenizer Token Details
Token RangeMinimum token value: 0 (pad token when `pad_with_end` is False)
Maximum token value: Size of the vocabulary - 1
Special TokensStart token: Typically 49406
End token: Typically 49407
Maximum Length`max_length`: 77 (default, can be set in the constructor)
`max_tokens_per_section`: 75 (max_length - 2)
Note: The actual vocabulary size and special token values may vary depending on the specific CLIP tokenizer used.
SD1Tokenizer クラスでは、トークンの範囲が以下のように設定されています:
最小トークン値:
基本的に 0 です。これは `pad_with_end` が False の場合のパディングトークンとして使用されます。
最大トークン値:
明示的には設定されていませんが、使用される CLIPTokenizer の語彙サイズによって決まります。
通常、CLIP モデルの語彙サイズは 49408 ですので、最大トークン値は 49407 になります。
特殊トークン:
開始トークン(start_token): 通常 49406
終了トークン(end_token): 通常 49407
最大長:
`max_length`: デフォルトで 77 に設定されています(コンストラクタで変更可能)
`max_tokens_per_section`: `max_length - 2` で、通常は 75 になります
これらの値は、使用される具体的な CLIP トークナイザーによって若干異なる可能性があります。また、このコードでは埋め込み(embeddings)も扱えるようになっており、これらは通常のトークン範囲外の値を持つ可能性があります。トークナイザーの実装上、0 から語彙サイズ-1 までの整数値がトークンとして使用されます。特殊トークン(開始、終了、パディング)も含めて、この範囲内に収まるように設計されています。全てのトークンをバッチに分けたら、最後のバッチも空欄を追加して75トークンにします。
Claudeによるソースコード分析は便利で丁寧です。
他にもこんな質問もできます。
この処理はどこで扱われますか?
1.1 倍の重みになる (a b c d e) と、
数値指定有りでその倍数になる (a b c d e:1.1)
質問ありがとうございます。その特定の処理は、`token_weights` 関数内で行われています。この関数を詳しく見てみましょう。
def token_weights(string, current_weight):
a = parse_parentheses(string)
out = []
for x in a:
weight = current_weight
if len(x) >= 2 and x[-1] == ')' and x[0] == '(':
x = x[1:-1]
xx = x.rfind(":")
weight *= 1.1
if xx > 0:
try:
weight = float(x[xx+1:])
x = x[:xx]
except:
pass
out += token_weights(x, weight)
else:
out += [(x, current_weight)]
return out
この `token_weights` 関数は、括弧で囲まれたテキストとその重みを処理します。具体的には(略)
この関数により、(a b c d e)`は1.1倍の重みを持ち、(a b c d e:1.1) は指定された1.1倍の重みを持つようになります。また、これらの構造がネストされている場合も適切に処理されます。
この処理の結果は、その後 `tokenize_with_weights` メソッド内で使用され、各トークンに適切な重みが割り当てられます。
AUTOMATIC1111にはプロンプトの文法やトークン数のチェックを行う補助機能がありますが、ComfyUI にはありません。 これはComfyUI の自由度との引き換えになります。しかもAUTOMATIC1111WebUIとは文法は同じでも中身は全然違うようです。AUTOMATIC1111内部ではCLIPの隠れ層出力に重み付けをしたあと、元の平均で正規化します。つまりあるトークンを強くしようとすると、他のトークンは弱くなるようです。ComfyUIでは単に定数倍するのではなく、空文によるCLIP出力を基準に重み付けします。正規化はしないので、重みをつけたトークンのみが影響を受けます。
このような「CLIPでプロンプトをどのように扱っているか?」はソースコードを直接読んだり分析したりする以外は、モデルとの対話を通して推測することができます。
AUTOMATIC1111WebUIにおいては「BREAK構文」や、オープンソースで数多くの拡張機能やテクニックが開発されてきました。例えば日本人が開発したExtentions「Regional Prompter」を使うことで複数の特徴を持つ人物を同時にプロンプトで表現できるようになります。
これから解説する「Concat Conditioning」はComfyUIにおいてAUTOMATIC1111の「BREAK構文」を実装するものです。複数のCLIP出力を結合します。
分割位置の明示的な指定
プロンプトは最初にトークン化されます。
トークン化されたプロンプトは、最大長(デフォルト77トークン)のバッチに分割されます。
各バッチは開始トークン(START_TOKEN)、プロンプトのトークン(最大75トークン)、終了トークン(END_TOKEN)、必要に応じてパディングトークンで構成されます。
8トークン以上の「長い単語」は、複数のバッチにまたがって分割される可能性があります。
バッチ間で直接的な文脈の共有はありません。
各バッチは独立して処理されます。
モデルは各バッチを個別に処理するため、バッチ間の長距離の依存関係は失われる可能性があります。
しかし、全てのバッチが同じプロンプトの一部であるため、全体的なテーマや文脈は維持される傾向があります。
つまりComfyUIにおいて「長いプロンプトをそのまま1つのCLIPに入力した場合、意図しない位置で分割され、その文脈が無視される可能性がある」ということは知っていてください。しかしこの特性を利用することで、プロンプトレベルで「描き分け」や「色分け」を明示的に行うことができます。
Conditioning(Concat)ノードの実装
Conditioning(Concat)ノードを使って「色分け」を実装してみましょう。
Concatとは「結合」、という意味です。
標準ワークフローを改造し、以下のプロンプトを意図した位置で分割し、「色分け」を明示的に行った画像を生成してみます。使用するプロンプトは以下になります。
A fantasy landscape, a red castle on a hill, overlooking a vast green forest,「広大な緑の森を見下ろす丘の上の赤い城」という「緑の森」と「赤い城」が混在するプロンプトです。
普通に生成するとこのような画像になります。色が混ざってしまう事が多くなり、制御性が低く、運任せになってしまいます。


これを「赤い城」と「緑の森」をそれぞれ複数のCLIPで表現できるようになれば制御性がよさそうです。
メニューの「Load Default」をクリックし、標準のワークフローをロードした状態にします。前回の続きで改造しても構いません。
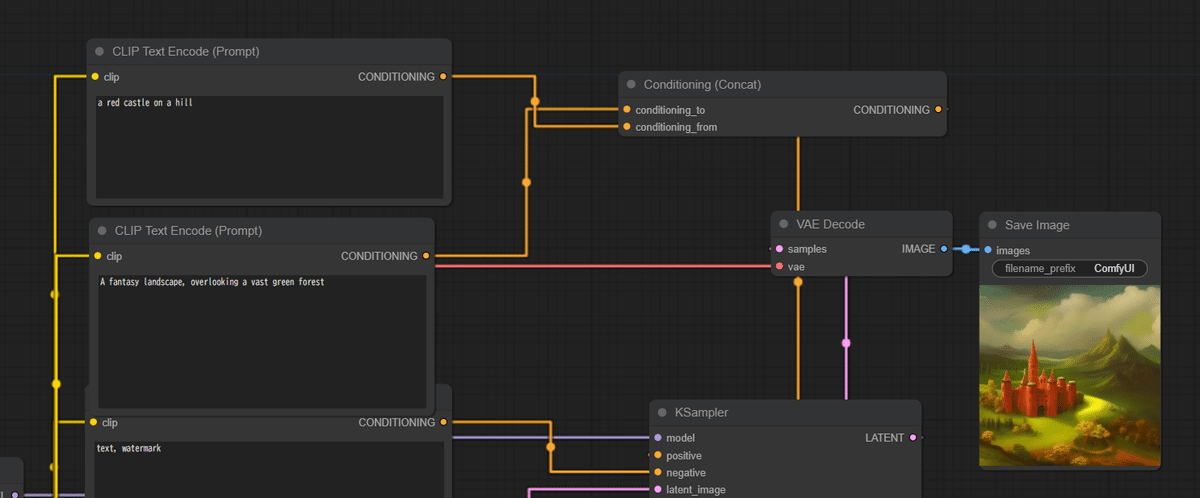
ポジティブプロンプト用のCLIPTextEncodeノードを1つ追加します。

1つ目のCLIPTextEncodeノードのプロンプトに「a red castle on a hill」と入力します。これをCLIP1と呼ぶことにします。
2つ目のCLIPTextEncodeノードのプロンプトに「A fantasy landscape, overlooking a vast green forest」と入力します。これをCLIP2と呼ぶことにします。

Conditioning(Concat)ノードを作成し、2つのCLIPTextEncodeノードの出力を接続します。

Conditioning (Concat)ノードの入力「conditioning_to」と「conditioning_from」をそれぞれ2つのCLIPを接続します。
どちらのCLIPを to と from につなぐのかは、この段階ではどちらでも構いません(後ほど解説します)。
Conditioning (Concat)ノードの出力をKSamplerのpositive入力に接続します。

以下が最終的なワークフローになります。
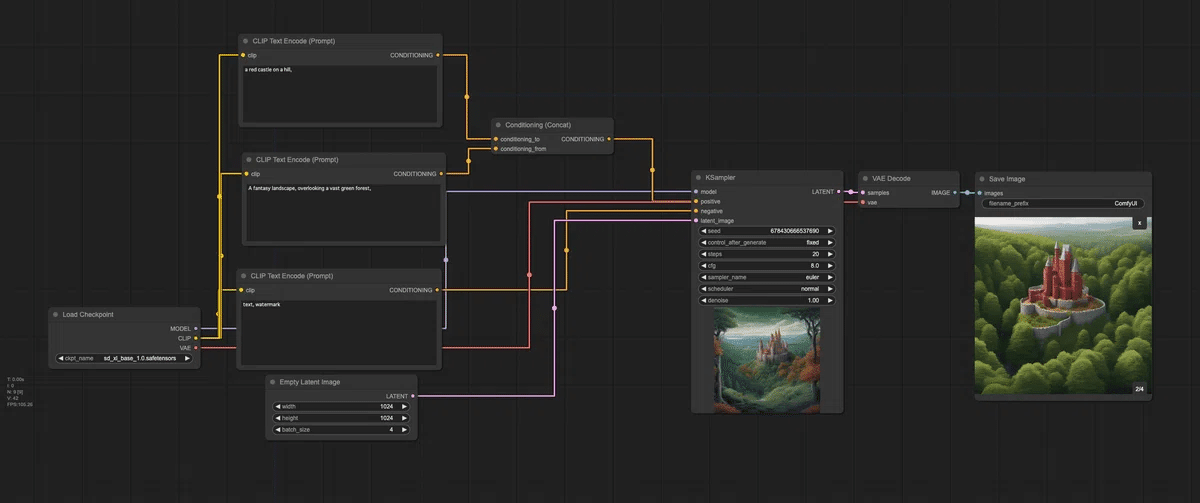
これでCLIP1が「丘の上の赤い城」、CLIP2が「広大な緑の森を見下ろす幻想的な風景」となり、それぞれがConcatを通して条件づけされることになります。どんな画像が生成されるのでしょうか。
以下の画像は、分割前と分割後の比較画像になります。分割前は、森は緑ですが、丘が赤くなっています。分割後は、城だけが赤くなっていることが確認できます。

Default workflowにて「a red castle on a hill,
A fantasy landscape, overlooking a vast green forest」(1344x768, seed:13)

CLIP1「a red castle on a hill」(1344x768, seed:13)
CLIP2「A fantasy landscape, overlooking a vast green forest」

Conditioning_toとConditioning_fromの意味
今回の実装例ではConditioning_toとConditioning_fromは「どちらのCLIPに接続しても構いません」としましたが、実際のプロンプトで絵作りをする時にはどのような意味を持っているのでしょうか。まずは入れ替えてみます。

Conditioning_to: a red castle on a hill
Conditioning_from: A fantasy landscape, overlooking a vast green forest
512x512, seed:12

Conditioning_to: A fantasy landscape, overlooking a vast green forest
Conditioning_from: a red castle on a hill
512x512, seed:12
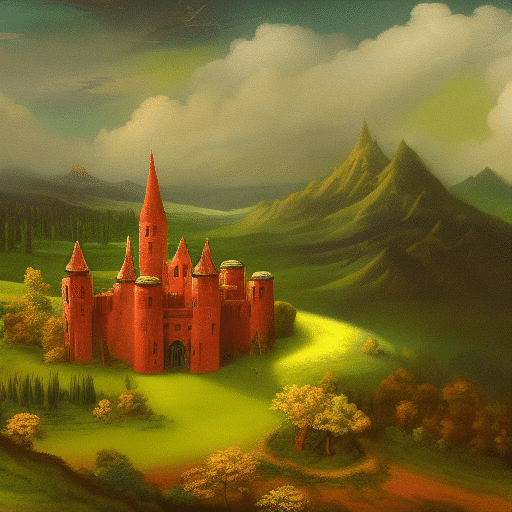
絵的にはほとんど変化がありません。しかしこれはプロンプトが短すぎるせいかもしれません。
SDXLを使った実験は次回に行うとして、今回は、このノードのソースコードを使って、Claudeに内部の定義を聞いてみましょう。
Claudeによる解説
ConditioningConcatクラスの concat メソッドを詳しく見てみると、conditioning_to と conditioning_from には実際に違いがあります。以下にその違いを説明します。
役割の違い:
conditioning_to は主要な条件付けであり、修正される対象です。
conditioning_from は付加的な条件付けで、conditioning_to に追加されます。
処理方法:
メソッドは conditioning_to の各要素に対してループを行います。
conditioning_from は最初の要素のみが使用されます。
連結(Concatenation)の方法:
conditioning_to の各要素の最初のテンソルが、conditioning_from の最初の要素の最初のテンソルと連結されます。
メタデータの扱い:
conditioning_to の各項目のメタデータ(2番目の要素)は保持されます。
conditioning_from のメタデータは使用されません。
出力構造:
出力は conditioning_to の構造を維持しつつ、各要素が連結によって修正されます。
つまり、英語の「to」と「from」の直感的な意味とは逆で、正しい覚え方は
「conditioning_to」がベースとなるプロンプトまたは主要な条件付け
「conditioning_from」が追加または補足的な条件付け
ということになりそうです(何度か確認しました)。
以上、Conditioning(Concat)ノードと複数CLIPを結合して「プロンプトの限界」を超え、その内部動作をソースコードから確認しました。
次回は実験を通して確認していきたいと思います。
具体的にはこんな絵を作ってみます。

まとめ:変化しつつある画像生成AIの常識
これまで3回にわたってComfyUIでSDXLのプロンプトを記述する基本的な方法から、応用的なテクニックまでを紹介してきました。画像生成AIが登場したばかりの頃のTextToImage、特にプロンプトは、かつては試行錯誤を通してテキストや構造を工夫することが中心でしたが、AUTOMATIC1111とComfyUIのCLIPの扱いが大きく変わっていることに気づかれたと思います。
AICUでは従来のような仮説や構造、文法や有効なワードを探求するだけでなく、ChatGPTやClaudeなどのLLMを使ってプロンプトそのものをメタに扱ったり、ソースコードを分析して正しい解釈を得たり、実験をして確かな情報を獲得していく方法が重要と考えて記事中で提案しています。次回はさらに実用的に、今回の内容を使って「複数のキャラクターを同時制御する」という実験を行います。様々なプロンプトを試してみて、自分にとって最適な表現方法を見つけてみましょう。
ComfyUIは、非常に強力な画像生成ツールです。プロンプトの力を最大限に活用することで、あなたの創造性を形にすることができます。ぜひ、色々なプロンプトを試して、素晴らしい画像を生み出してください!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!