

[ComfyMaster35] ここから始める動画編!SDXL+AnimateDiffでテキストから動画を生成しよう! #ComfyUI [無料]

Stable Diffusionをベースに開発されたAnimateDiffは、シンプルなテキストプロンプトから動画を簡単に作成できます。画像生成AIを使って動画を生成する基本を知りたい方に向けて、この記事で一気に詳しく解説しています。
※本記事はワークフロー含め、期間限定無料で提供します!
[PR] ComfyUIマスター:カスタムノードとアプリ開発
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第35回目、ついに動画編に突入です!
本記事では、SDXLとAnimateDiffを用いて、テキストから動画を作成する方法を説明します。AnimateDiff単体では、生成された動画は一貫性を保持しにくいですが、その原因と緩和方法をあわせて解説していきます。
[ComfyMaster34] 便利LoRA紹介: Detail Tweaker XLで画像の精細さをコントロール #ComfyUI
1. AnimateDiffの概要
AnimateDiffとは
AnimateDiffは、Stable Diffusionをベースに開発された画像から動画を生成するtext-to-video(t2v)の技術です。既存のtext-to-image(t2i)モデルを特別な調整なしにアニメーション生成モデルに変換する実用的なフレームワークであり、これにより、ユーザーは高品質な画像生成能力を持つt2iモデルを、そのまま滑らかで視覚的に魅力的なアニメーションを生成するために活用できるようになります。
AnimateDiffの仕組み
AnimateDiffの核心は「モーションモジュール」という、事前にトレーニングされたプラグアンドプレイのモジュールにあります。このモジュールは、リアルな動画データからモーションプライア(Motion Priors)を学習しており、一度トレーニングされると、同じ基盤となるT2Iモデルを使用する他のパーソナライズT2Iモデルにもシームレスに統合可能です。具体的な仕組みは以下の3つのステップに分かれます。
モーションプライア(Motion Priors)とは?
モーションプライアとは、動画データから学習される「動きの先行知識」を指します。これには以下の特徴があります。
動きのパターンの学習:モーションプライアは、動画の連続フレーム間の変化やダイナミクスを捉え、自然な動きを再現します。
汎用性の確保:一度学習されたモーションプライアは、異なるt2iモデルにも適用可能で、モデルごとに動きを学習し直す必要がありません。
高品質なアニメーション生成:モーションプライアにより、生成されるアニメーションが時間的な一貫性と滑らかさを持ちます。
1. ドメインアダプターの導入
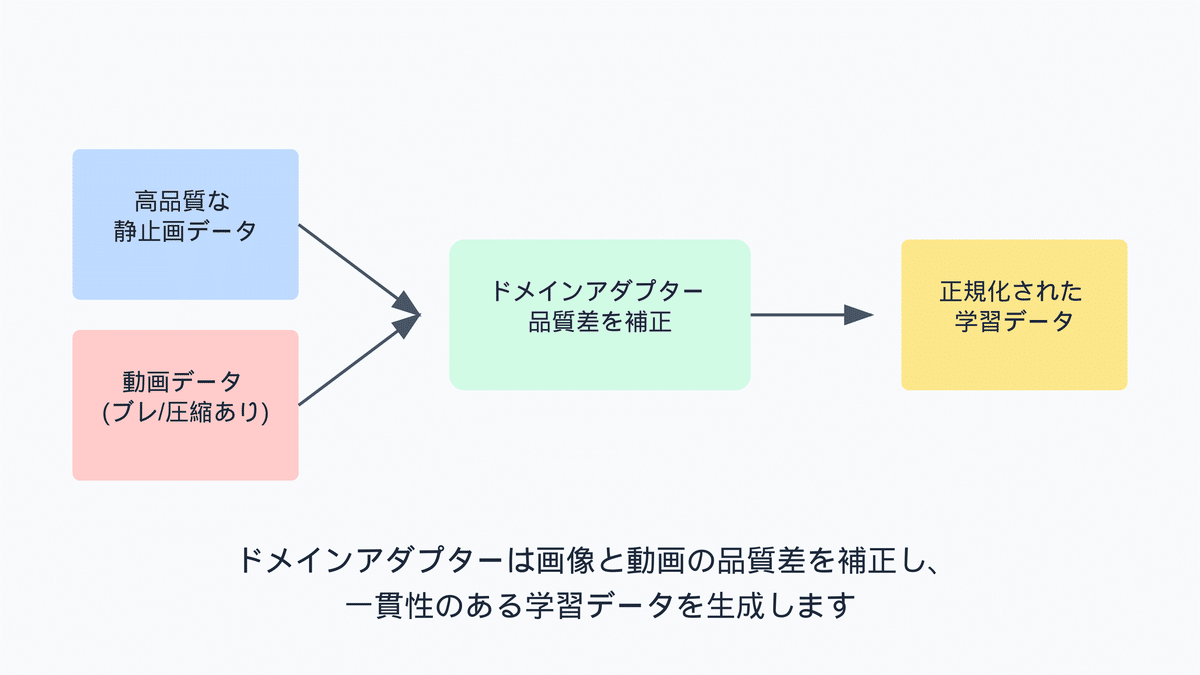
AnimateDiffでは、まず「ドメインアダプター」と呼ばれる別のネットワークを導入します。これは、画像データと動画データの間に存在する画質や内容の違いを補正するためのものです。動画データはしばしば動きのブレや圧縮アーティファクト、ウォーターマークが含まれるため、直接学習させるとアニメーションの品質が低下する恐れがあります。ドメインアダプターを用いることで、モーションモジュールはモーションプライアのみを学習し、画像の質に関する情報は元のT2Iモデルが保持します。
2. モーションモジュールの学習

次に、「モーションモジュール」を学習します。これは、動画データから動きのパターンであるモーションプライアを抽出し、アニメーション生成に必要な時間的なダイナミクスをモデルに追加する役割を担います。モーションモジュールは、Transformerアーキテクチャをベースにしており、動画の各フレーム間の関連性を学習します。このモジュールをT2Iモデルに統合することで、生成される画像が時間とともに自然に動くアニメーションへと変換されます。
3. MotionLoRAによる動きのパターンの微調整

最後に、「MotionLoRA」と呼ばれる軽量な微調整技術を用います。これは、既に学習済みのモーションモジュールを新しい動きのパターンに適応させるためのもので、例えばカメラのズームインやパンニングといった特定の動きを追加したい場合に使用します。MotionLoRAは少数の参考動画と短時間のトレーニングで新しい動きのパターンを学習できるため、ユーザーは簡単に特定の効果を追加できます。
AnimateDiffの利点
AnimateDiffの主な利点は以下の通りです。
モデル固有の調整が不要: 既存のt2iモデルをそのままアニメーション生成に活用できるため、ユーザーは手間をかけずにアニメーションを作成できます。
高品質なアニメーション: モーションモジュールがモーションプライアを学習することで、生成されるアニメーションは自然で視覚的に魅力的です。
柔軟な動きのカスタマイズ: MotionLoRAを用いることで、特定の動きのパターンを簡単に追加・調整できます。
効率的なトレーニングと共有: MotionLoRAは少量のデータと短時間のトレーニングで動きを学習できるため、ユーザー間でのモデル共有も容易です。
2. カスタムノードのインストール
さて早速はじめていきましょう。
ComfyUIでのカスタムノードのインストール方法があやふやな方はこちらを復習お願いいたします。
★復習[ComfyMaster4]ComfyUIカスタムノード導入ガイド! 初心者でも安心のステップバイステップ解説
Google ColabでのComfyUI環境設定から学びたい方はこちら
★復習[ComfyMaster1] Google ColabでComfyUIを動かしてみよう!
準備ができたら、以下のカスタムノードを使用するため、ComfyUI Managerからインストールしてください。
ComfyUI-AnimateDiff-Evolved
ComfyUI-AnimateDiff-Evolvedは、Stable Diffusionモデルを拡張して動画生成を可能にするカスタムノードです。元のAnimateDiffを進化させたバージョンで、動画生成のためのモーションモジュールと高度なサンプリング技術を組み込んでいます。
ComfyUI-VideoHelperSuite
ComfyUI-VideoHelperSuiteは、動画生成を支援するためのカスタムノードです。動画の編集や加工を容易にする機能を提供します。今回は、一連の画像を動画にして保存するノードを使用するために必要となります。
3. モデルのインストール
RealVisXL V5.0 Lightning
今回は、RealVisXLのLightningバージョンを使用します。Lightningバージョンでは、サンプリングのステップ数を4-6回に抑えることができます。生成量の多いAnimateDiffでは、TurboやLightningなどの数ステップで生成完了するモデルを選ぶと良いでしょう。
以下のリンクよりモデルをダウンロードし、「ComfyUI/models/checkpoints」フォルダに格納してください。
SDXL Motion Module
SDXLのモデルで動画生成するため、SDXLのモーションモジュールをダウンロードします。SDXLのモーションモデルには、「AnimateDiff-SDXL」と「Hotshot-XL」の2種類があります。AnimateDiff-SDXLは16フレーム、Hotshot-XLは8フレームのコンテクストに対応しており、AnimateDiff-SDXLのコンテクストは長く、一貫した動画を作成しやすいですが、一方で品質が悪いことが指摘されています。詳細は、以下のIssueをご確認ください。
今回は、両方のモデルを使用してみます。それぞれ以下よりダウンロードし、「ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/models」フォルダに格納してください。
AnimateDiff-SDXL
Hotshot-XL
4. ワークフローの解説
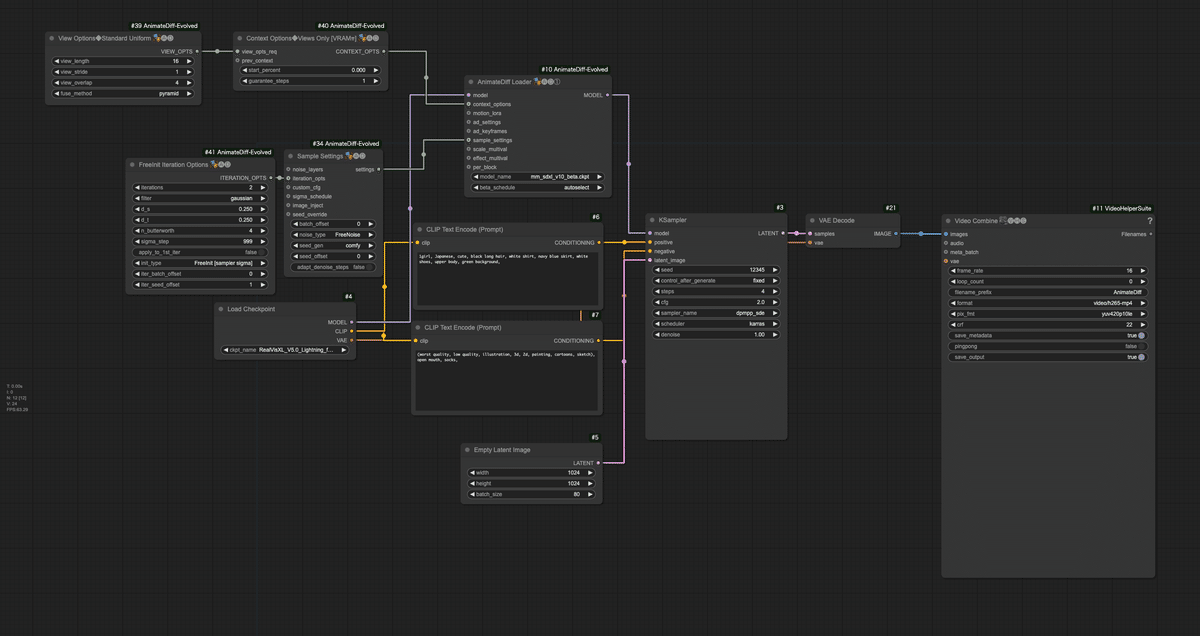
以下がワークフローの全体像になります。このワークフローは、テキストプロンプトから直接アニメーション動画を生成する簡潔な例です。AnimateDiffを使用することで、フレーム間の一貫性を保ちながら滑らかなアニメーションを生成します。低ステップ数(4ステップ)での高速生成を行いながら、AnimateDiffの特性を活かして品質を維持しています。
ワークフローは、以下のリンクよりダウンロードしてください。
ワークフロー(右クリックで保存)
このワークフローの構造を以下の通りにフローチャートで表現します。

以下に、このワークフローの主要な部分とその機能を詳細に説明します。
モデルとAnimateDiffの設定:
Load Checkpoint ノード: 「RealVisXL_V5.0_Lightning_fp16.safetensors」モデルを読み込みます。
AnimateDiff Loader ノード: AnimateDiffのモーションモジュールをベースモデルに適用します。
model_name: 「mm_sdxl_v10_beta.ckpt」または「hsxl_temporal_layers.fp16.safetensors」を設定します。
beta_schedule: autoselect
Context Options Standard Uniformノード: AnimateDiffのコンテキストオプションを設定します。
context_length: 16(Hotshot-XLの場合は8)
context_stride: 1
context_overlap: 4
fuse_method: pyramid
use_on_equal_length: false
start_percent: 0
guarantee_steps: 1
Sample Settingsノード: アニメーション生成プロセスの様々な要素をコントロールするための設定をまとめるノード
noise_typeをFreeNoiseに設定します。FreeNoiseは、FreeInitという、動画生成モデルにおける時間的一貫性を向上させるための手法を利用して各フレームを生成します。これにより、一貫性を持った動画を作成しやすくなります。コンテクスト間で一貫性を保てる一方、FreeNoiseを使用しない場合と比較して、変化が小さくなります。
サンプリング設定:
FreeInit Iteration Optionsノード: FreeInit samplingのパラメータを設定します。
Sample Settingsノード: AnimateDiffのサンプリング設定を構成します(FreeNoiseモード)。
プロンプト処理:
ポジティブプロンプト: 「1girl, Japanese, cute, black long hair, white shirt, navy blue skirt, white shoes, upper body, green background,」
ネガティブプロンプト: 「(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth, socks,」
潜在画像の準備:
Empty Latent Image ノード: 1024x1024の80フレームの空の潜在画像を生成。
Hotshot-XLは、次の解像度でトレーニングされているため、次の解像度のいずれかを設定してください: 320 x 768、384 x 672、416 x 608、512 x 512、608 x 416、672 x 384、768 x 320
画像生成:
KSampler ノード:
Seed: 12345
Steps: 4
CFG Scale: 2
Sampler: dpmpp_sde
Scheduler: karras
Denoise: 1.0
出力処理:
VAE Decode ノード: 生成された潜在表現を実際の画像にデコードします。
Video Combine ノード: 生成された画像シーケンスを16fpsの動画に変換し、「AnimateDiff」というプレフィックスで保存します。
5. ワークフローの補足
Context OptionsとView Options
通常、モーションモジュールでは、短いフレーム数しか扱えない(AnimateDiffは16フレーム、HotshotXLは8フレーム)です。これをかいかつするのがContext OptionsとView Optionsです。これらは、アニメーションを作成する際に、AnimateDiffやHotshotXLといったモデルの制限を超えて、より長いアニメーションを作るための方法です。
Context Optionsは、アニメーションの一部ずつを処理する方法です。これにより、同時に使うメモリ(VRAM)の量を制限できます。要するに、大きな作業を小分けにして進めることで、VRAMの負担を減らしているのです。これには、Stable Diffusionの拡散処理やControlNetなどの補助技術が含まれます。
View Optionsは、モーション(動き)を処理するモデルが、見るべきデータ(潜在変数)を小分けにする方法です。この方法ではVRAMを節約できませんが、処理が安定しやすく、より速く動きます。なぜなら、データが全ての処理を経る必要がないからです。
Context OptionsとView Optionsの違いは、Context Optionsがメモリを節約して少しずつアニメーションを処理するのに対し、View Optionsはメモリの節約はできませんが、速くて安定しています。
この2つを組み合わせることで、長くて安定したアニメーションを作りながら、VRAMの使用量をうまく調整することができます。VRAMに余裕がある場合は、処理をより速く行うためにView Optionsをメインに使うこともできます。
Sample Settings
「Sample Settings」ノードは、通常のKSamplerノードでは設定できないサンプリングプロセスをカスタマイズするための機能を提供します。デフォルトの設定では何の影響も与えないため、安全に接続しても動作に変更はありません。
Sample Settingsのnoise_typeで生成されるノイズのタイプを選択できます。この中のFreeNoiseは、安定性を増すために利用できます。FreeNoiseは、FreeInitという、動画生成モデルにおける時間的一貫性を向上させるための手法を用いています。この方法は、追加のトレーニングを行うことなく、ビデオ拡散モデルを使用して生成された動画の全体的な品質を改善します。
基本的に最初のcontext_lengthウィンドウと同じ初期ノイズをコンテキストの重複部分で再利用し、それ以降のコンテキストウィンドウの重複部分にはランダムにシャッフルされたバージョンを配置します。コンテキストウィンドウの重複部分でノイズをシャッフルしないため、context_lengthフレームごとに内容が繰り返されるという副作用があります。
FreeInit イテレーションオプション
前述したFreeInitの特性上、FreeInitはイテレーションが最低2回必要になります。FreeInitの動作としては、最初のイテレーションで生成された動画から低周波のノイズを取得し、それをランダムに生成された高周波のノイズと組み合わせて次のイテレーションを実行します。各イテレーションは完全なサンプルであり、イテレーションが2回行われると、1回またはイテレーションオプションが接続されていない場合に比べて実行時間が2倍になります。
FreeInit [sampler sigma]: この方法は、サンプラーから得られるシグマ値を使用してノイズを適用します。既存の潜在変数からの低周波ノイズとランダムに生成された潜在変数からの高周波ノイズを組み合わせることで、アニメーションの時間的一貫性を高めることを目的としています。
FreeInit [model sigma]: この方法は、サンプラーではなくモデルからシグマ値を使用します。カスタムKSamplerを使用する際に特に有用で、ノイズの適用がモデルの特性と一致するようにします。
DinkInit_v1: これはFreeInitの初期実装で、開発者が方法をさらに洗練する前に作成されたものです。他の2つのオプションほど最適化されていないかもしれませんが、特定のコンテキストで満足のいく結果を得ることができます。
6. ワークフローの実行
それでは、ワークフローを実行してみましょう。マシンスペックにもよりますが、5秒の動画を生成するにも多くの時間を要します(A100のGPUで1分、A6000で3分ほどでした)。
AnimateDiff-SDXLの結果
以下は、Sample Settingsを適用しない場合の生成結果です。プロンプトに従い女性の動画が生成されていますが、一貫性がないことが分かります。これは、AnimateDiffの特性で、Context Optionsノードのcontext_length内でしかコンテクストを正しく保持できないためです。context_overlapで数フレームをオーバーラップさせることで、次のコンテクストでの生成に前の生成結果を反映させますが、それも限界があるようです。

次にSample Settingsのnoise_typeをFreeNoiseにして生成結果です。先ほどよりも変化が少なく、コンテクスト間で一貫性が保たれていることが分かります。

その他に、一貫性を保つ方法として、Motion LoRAを使う方法があります。しかし、Motion LoRAは、SD1.5用しか存在せず、SDXLには適用できません。SD系列だと、SDXLがメジャーになっている中で、SD1.5を使用する人はあまりいないと思います。そのため、これがSDXL+AnimateDiffでのt2vの限界だと思います。ただし、この特性を活かした面白い表現をしたり、抽象的な表現をするには十分にAnimateDiffを活かせると思います。
Hotshot-XLの生成結果
次は、Sample Settingsのnoise_typeをdefautで、モーションモデルにHotshot-XLを使用して生成した結果です。コンテクスト長が8フレームしかないため、0.5秒ごとにコンテクストが変わってしまい、AnimateDiff-SDXL以上に変化の激しい動画となっています。

次にSample Settingsのnoise_typeをFreeNoiseにして生成した結果です。AnimateDiff-SDXLと同様、先ほどよりも一貫性が増しました。Hotshot-XLの方がAnimateDiff-SDXLより明瞭だと言われますが、対応している解像度がAnimateDiff-SDXLは1024x1024、Hotshot-XLは512x512なので、解像度が異なることもあり、違いが分かりづらいです。Hires.fixすれば、どちらもそれほど気にならないかもしれません(text2videoに限れば)。

7. まとめ
AnimateDiffは、Stable Diffusionの技術を基に、画像生成AIの枠を超えて動画生成を実現した画期的なツールです。軽量でありながら、自然で一貫性のあるアニメーションを生成できるため、クリエイティブな用途に広く活用が期待されます。特に、テキストプロンプトから直接アニメーションを生成できる点は、デザイナーやアニメーターにとって大きな利便性を提供します。
しかし、現状ではContext Optionsノードの制約やMotion LoRAの対応が限定的で、完全に安定した結果を得るためには工夫が必要です。今後、SDXLシリーズに最適化された技術の進展により、さらに質の高い動画生成が可能になることが期待されます。
新しい技術に挑戦し続けることは、より高品質で魅力的なコンテンツを生み出す力となります。AnimateDiffを駆使して、これまでにないアニメーション表現に挑戦してみてください。
次回は、AnimateDiffでvideo-to-video(v2v)をする方法を紹介します。乞うご期待!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
[PR] ComfyUIマスター:カスタムノードとアプリ開発
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!