

Google Colab で試す Stable Cascade での新時代のテキスト画像生成

2024年2月13日、Stability AIより新モデル「Stable Cascade」がリリースされました。
https://ja.stability.ai/blog/stable-cascade
🚀【新登場】新しいテキストから画像への変換モデル、Stable Cascadeを紹介します。Würstchenアーキテクチャを基に、誰でも簡単にトレーニングと微調整ができるよう設計されています。🎨… pic.twitter.com/hKbaVvyKgH
— Stability AI Japan (@StabilityAI_JP) February 13, 2024
🚀【新登場】新しいテキストから画像への変換モデル、Stable Cascadeを紹介します。Würstchenアーキテクチャを基に、誰でも簡単にトレーニングと微調整ができるよう設計されています。🎨
非商用利用に限り、チェックポイントと推論スクリプトを提供。微調整やControlNet、LoRAトレーニングのためのスクリプトも公開中!🔍
💡高品質、柔軟性、効率性を重視し、ハードウェアの制約を超えたこの革新的アプローチをぜひ体験してください。
詳細はこちら→ https://ja.stability.ai/blog/stable-cascade
Stable Cascade モデルカードより
このモデルは、Würstchenアーキテクチャに基づいて構築されており、Stable Diffusionのような他のモデルとの主な違いは、より小さな潜在空間で動作していることです。これはなぜ重要なのでしょうか?潜在空間が小さければ小さいほど、推論をより速く実行することができ、トレーニングがより低コストになります。
潜在空間はどのくらい小さいのかというと、Stable Diffusionは圧縮率8を使用し、1024x1024の画像を128x128にエンコードしています。Stable Cascadeは42の圧縮率を達成し、1024x1024の画像を24x24にエンコードすることができます。そして、テキスト条件モデルは、高度に圧縮された潜在空間で学習されます。このアーキテクチャの以前のバージョンでは、Stable Diffusion 1.5と比較して16倍のコスト削減を達成しました。
したがって、この種のモデルは効率が重要な用途に適しています。さらに、ファインチューニング、LoRA、ControlNet、IP-Adapter、LCMなどの既知の拡張はすべて、この方法でも可能です。
モデルの詳細
Stable Cascadeは、テキストプロンプトから画像を生成するように学習された拡散モデルです。
開発者:Stability AI
資金提供者:Stability AI
モデルの種類:テキスト画像生成モデル
モデルソース
研究目的には、StabilityCascadeのGithubリポジトリ
(https://github.com/Stability-AI/StableCascade )をお勧めします。
リポジトリ: https://github.com/Stability-AI/StableCascade
論文:https://openreview.net/forum?id=gU58d5QeGv
"Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models", Pablo Pernias, Dominic Rampas, Mats Leon Richter, Christopher Pal, Marc Aubreville, Published: 16 Jan 2024, ICLR 2024 oral
モデルの概要
Stable Cascadeは3つのモデルで構成されています: Stage A、Stage B、Stage Cの3つのモデルで構成され、画像を生成するためのカスケードを表現しています。ステージAとステージBは、Stable DiffusionにおけるVAEの仕事と同様に、画像を圧縮するために使用されます。しかし、このセットアップでは、より高い画像圧縮を達成することができます。Stable Diffusionモデルが空間圧縮係数8を使用し、1024 x 1024の解像度の画像を128 x 128にエンコードするのに対し、Stable Cascadeは42の圧縮係数を達成します。これにより、1024 x 1024の画像を24 x 24にエンコードしながら、画像を正確にデコードすることができます。これには、学習と推論をより安価に行えるという大きな利点があります。さらに、ステージCは、テキストプロンプトが与えられると、24 x 24の小さな潜在能力を生成する役割を果たします。
次の図はこれを視覚的に示しています。

今回のリリースでは、ステージCのチェックポイントを2つ、ステージBのチェックポイントを2つ、ステージAのチェックポイントを1つ用意しています。ステージCには10億と36億のパラメータ・バージョンがありますが、微調整に最も労力を費やした36億バージョンの使用を強くお勧めします。ステージBは7億と15億のパラメーター。どちらも素晴らしい結果をもたらしますが、15億の方が小さく細かいディテールの再構築に優れています。従って、それぞれの大きい方のバージョンを使用した方が、最良の結果が得られます。最後に、ステージAは2,000万個のパラメータを含み、サイズが小さいため固定されています。

Stability AIの評価によると、Stable Cascadeはプロンプトのアライメントと美的品質の両方において、ほぼすべての比較で最高のパフォーマンスを発揮しました。上の図は、parti-prompts(リンク)と審美的なプロンプトをミックスしたものを使用した人間による評価の結果です。具体的には、Stable Cascade(推論ステップ数30)をPlayground v2(推論ステップ数50)、SDXL(推論ステップ数50)、SDXL Turbo(推論ステップ数1)、Würstchen v2(推論ステップ数30)と比較しました。
コード例
⚠️ 重要: 以下のコードを動作させるには、PRがWIPである間にこのブランチからディフューザーをインストールする必要があります。
※実際に動作するGoogle Colabのコードはこちら(AICUのリポジトリ)
https://j.aicu.ai/StableCascade
用途
直接使用
このモデルは今のところ研究用です。想定される研究分野と課題は以下の通りです。
・生成モデルの研究
・有害なコンテンツを生成する可能性のあるモデルの安全な展開。
・生成モデルの限界とバイアスの調査と理解。
・芸術作品の生成と、デザインやその他の芸術的プロセスにおける使用。
・教育的または創造的なツールへの応用。
除外される用途は以下の通り。
範囲外(Out-of-scope)の使用:想定の範囲外
このモデルは、人物や出来事の事実または真実の表現となるように訓練されていないため、そのようなコンテンツを生成するためにモデルを使用することは、このモデルの能力の範囲外です。このモデルは、Stability AI の利用規定に違反するような方法で使用しないでください。
制限とバイアス
制限事項
・顔や人物は一般的に正しく生成されない可能性があります。
・モデルの autoencoding 部分は非可逆です。
推奨事項
このモデルは研究目的でのみ使用できます。
モデルを始めるには
https://github.com/Stability-AI/StableCascade をチェックしてください。
AICU media編集部より
Würstchen(ヴルストヒェン)とは小さいソーセージのことです🌭
公式のモデルカードのコードをベースにTextToImageが実行できる Google Colabで動作するコードを試験公開します。
https://j.aicu.ai/StableCascade
(上記のライセンスに従い研究目的に限ります)
※ローカル環境での 公式 notebook はこちらに存在します。
https://github.com/Stability-AI/StableCascade/blob/master/inference/readme.md
T4 GPUでの実験

V100での実験
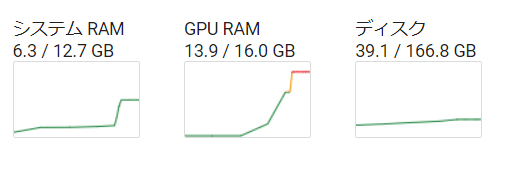
V100 ハイメモリ での実験

A100での実験

サンプルコードのt2iプロンプトはこのように指定されていました。
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""

かなり高精細な画像を生成しています。高圧縮にも関わらず、です。
いろいろ探っていきますが、1024x1024の画像生成自体は2秒で生成しています(A100環境)。
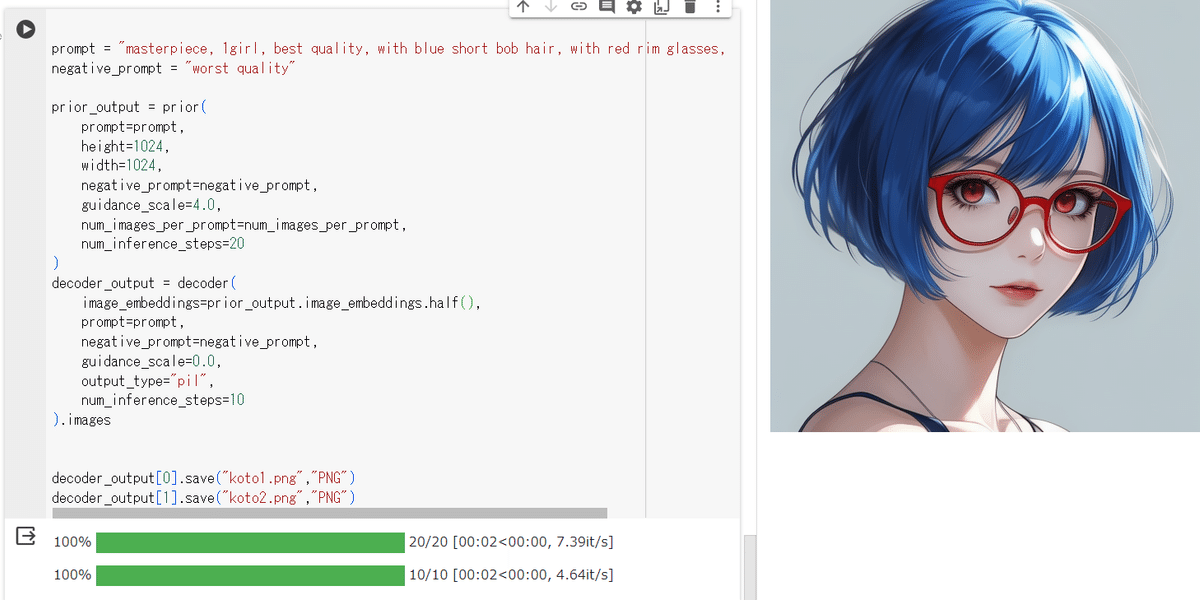
prior_output の画像サイズを変えることで横長画像も簡単に生成できます。
またネガティブプロンプトも標準装備です。

せっかくのバレンタインなので、こんな感じで生成していきます。




髪のリムライト、眉毛、まつ毛の描写、眼鏡の半透明の影が顔に落ちているあたりが素晴らしいですね。

GPU消費量は少しづつ上がっていきます。
初回にロードしたモデルで何度でも生成できる上に、画質も高精細です。
現在は研究目的に限定されていますが、今後、商用ライセンスが期待されますね。
またこの記事ではTextToImageのみ紹介いたしましたが、リポジトリの中にはリリース情報にあるように、従来の Stable Diffusion でオープンに開発されてきた、様々なユースケースのトレーニングスクリプトや実行例が存在しています。非常にシンプルなソースコード群になっています。
・Text to Image
・ControlNet
・LoRA
・画像再構成
Stable CascadeはStage AとBを使って画像を圧縮し、Stage Cはテキスト条件学習に使われます。したがって、LoRAやControlNetをStage Cのためだけにトレーニングするのは理にかなっています。
コードベースは開発初期です。予期せぬエラーや最適化されていないトレーニングや推論コードに遭遇するかもしれません。あらかじめお詫び申し上げます。もしご興味があれば、最新の改善と最適化を目指してアップデートを続けます。さらに、アイデアやフィードバック、あるいはアップデートに貢献してくださる方々からのご連絡をお待ちしております。
@misc{pernias2023wuerstchen,
title={Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models},
author={Pablo Pernias and Dominic Rampas and Mats L. Richter and Christopher J. Pal and Marc Aubreville},
year={2023},
eprint={2306.00637},
archivePrefix={arXiv},
primaryClass={cs.CV}
}追記:mkshingさんより著者陣にお祝いのツイート
Stable Cascade (Würstchen v3) by @dome_271 and @pabloppp is out!
— mkshing (@mk1stats) February 13, 2024
I've been a big fan of Würstchen since v1 but v3 is absolutely the best as their results are shown.
code: https://t.co/C42ZIBDo3n
Big congrats to both of you and @StabilityAI! https://t.co/ELbwEdxbf7 pic.twitter.com/an5sODdpyM
Stable Cascadeが Google Colab T4 16GBで動くコードも
Also, I hacked to run the Stable Cascade on Colab free plan (T4 16GB)!
— mkshing (@mk1stats) February 14, 2024
Enjoy! #stablecascade
colab: https://t.co/C33RSn5uSy
ありがとうございます!
いいなと思ったら応援しよう!
