

特集:日本企業のコンピュータサイエンス研究開発の2023年を総括する(中編) #CCSE2023

前編に引き続き、CCSE2023の講演レポートです。
Stability AIのJerry Chiさんに講演スライドをご共有いただきましたので、高品質なスライドと、AICU社ならではの音声文字起こし技術と調査技術で「読みやすい講演記録」としてお送りします。
Stability AI - Jerry Chi 講演録 in CCSE2023
2023/12/23, transcribed by AICU Inc.


なんかプロモーションっぽい話がいっぱいあって、恐縮です。一応の弊社の会社のビジョンですけれども、「人類の可能性を広げる共有ビルディングブロックとして『オープンな生成AI基盤モデル』を広く世界中の人々にご提供する」です。

ビルディングブロックというのは、ビルダー。例えば、起業家とか、開発者とかが、弊社のモデルを使って、それで役立つサービスやアプリを作っていけたらいいなと思っております。
弊社の社長は「全てのモダリティモダリティ」、例えば画像だったり、動画だったり3Dだったり、なんか「全部やる」って言ってます。本当は全部じゃないんですけれども。でも、メジャーなやつは大体やろうとしております。
Stability AIの沿革
多分一番大きかったイベントが去年の8月にあった Stable Diffusion のリリースですね。

これはドイツなどの研究グループと一緒に研究開発してリリースしたんですけれども、そのまま「オープンな生成AIブームの引き金となった」に言われています。


で、その後、そのモデルもバージョンアップして、日本支社を立ち上げて言語モデルを作り始めて。その後の日本のモデルも作り始めています。画像言語モデルだったり、Stable LM 、Japanese Stable LMという日本語の言語モデルだったり。あとはその Stable Diffusion XLのその大元の Stable Diffusion の進化版の日本語版みたいなものも作っております。

ちょっと後でもうちょっと詳しく説明します。
弊社は何が特別かっていうと「オープンでマルチモーダル」っていうキーワードがありまして、今はブラックボックスのAPI経由でしか使えないような、ChatGPTみたいなのも結構役だったと思いますけれども、オープンであるがゆえに、いろんなその世界やコミュニティとかいろんな会社や企業や個人やオンラインコミュニティがそのモデルをま自由に改造できて、自由に、いろんなファインチューニングや微調整して、いろんなユーケースに適用できるというメリットがあります。

日本は初めての、唯一の、ロンドン以外の全てのチームの機能を持つ拠点で、かなり日本マーケットとか日本のために頑張っていきたいと思います。

このオープンとマルチモーダル、国内外で研究開発というところが結構ユニークかなと思っています。

「3億枚の Stable Diffusion による画像を1分ごとに生成可能」
「3台のGPT-3を同時にトレーニング可能」
もちろん小さいスタートだと結構色々競争も激しいので、例えばAWSとパートナーになったり、インテルともまパートナーシップを結んだり。
最近、インテルからも資金調達しました。はい。
大企業は弊社のモデル、例えばインテルのCPUで速く走るように頑張ってます。
なので結構みんな「SAIのモデルで遊びたい」「使いたい」っていう時代になりましたね。

またプロモーションで恐縮ですけれども、世界中のいろんなメディア、タイムなどの雑誌から受賞したり。例えば Stable Audio がタイムのベスト100の発明にランキングしたり。

日本でも、グッドデザイン賞をSDXLが受賞。SDXLは日本チームが作ったわけじゃないんですけれども、その当時はまだ日本語版出てなかったんですよね。英語から画像を生成するAIとして、グッドデザイン賞を受賞しました。

日本チームが何やってるかと言いますと、各機能を持っていて、今日のみなさんは研究とエンジニアリングの話を一番興味をお持ちかと思いますけれど、マーケティングやコミュニティ形成とか、BizDev。いろんな日本企業とも提携して「いろいろ一緒にできないか」、有料の案件でも「無料でちょっとな手伝ってあげる」、「アドバイスをあげる」みたいなこともやっております。
要は日本で「いい生成AIの生態系」を作っていく。
それで、日本のクリエイターとか企業とか組織の皆さんエンパワーされて、最大限その生成AIを生かして、最大限のポテンシャルを発揮できたらいいな……っていうミッションを持っています。


日本チームはこんな感じで過半数が技術者です。例えばPh.D(博士)もたくさん採用しているっていう感じなんじゃないんですね。基礎研究はあまり多くなくて。でも例えばエンジニアリング力や応用研究の能力は高いと思います。
🌟 Generative Media Solutions Engineer 募集中🚀 📍
— Stability AI 日本公式 (@StabilityAI_JP) December 22, 2023
✨ メディア生成AIに情熱を持ち、ソフトウェア開発経験豊富な方、大歓迎!クリエイティブな才能を、世界を変える技術で発揮できます!
🔍 日本語・英語に加え、多様な技術スキルを活かせる場所です。
🚀…



海外のメンバーも本当にすごいですよね。正直その「元グーグル」とか「グーグルリサーチ」だったり。他も動画生成の「Runway」だったり。本当に世界中からいろんな研究者、研究のリーダーを開発者を採用いしてきています。
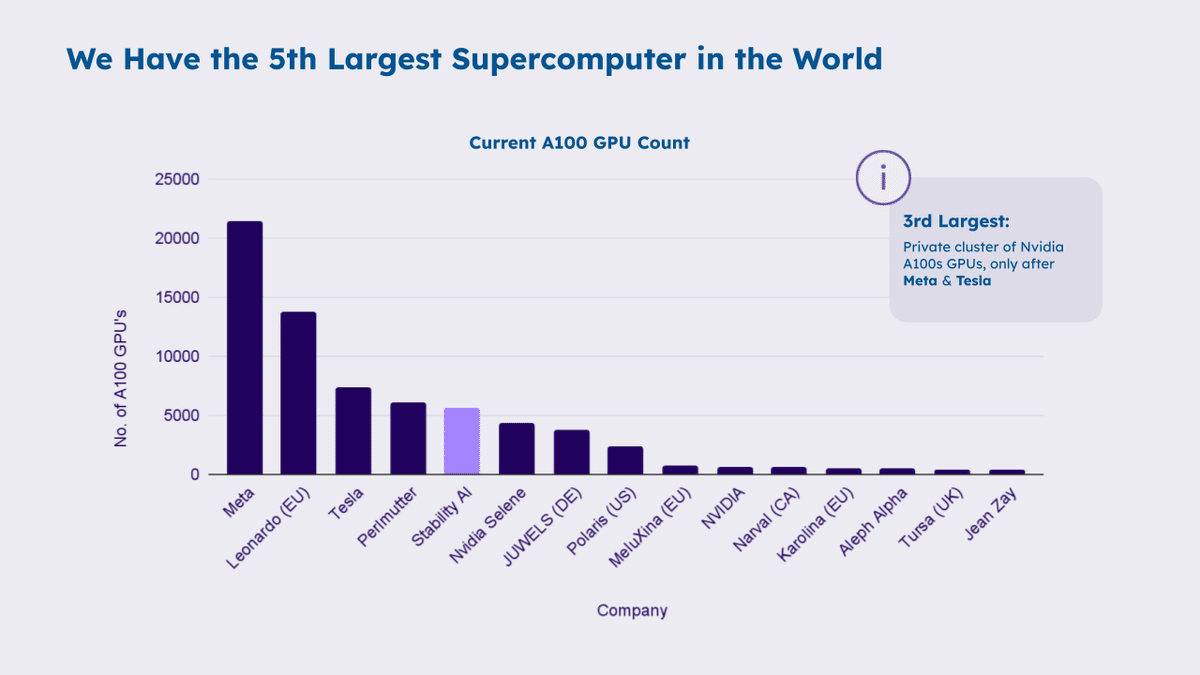
あとGPUもたくさん。ちょっと古い資料ですけれども、GPUもたくさん持っていて、AWSのGPU並列処理に最適化されたクラスターをもう数年間契約しましたので、これも研究開発者としてやりやすいかなと思います。でかいモデルを構築することができる。スーパーコンピュータ、先ほど言及したインテルとのパートナーシップ経由で、NVIDIA以外のチップ、GPUとか、Intel の Habana Gaudi*-2 っていうチップも、日本ではまだあまり知られてないんですけれども、実は「なんかすごいいけてるチップ」で、そこでも効率よくモデルの訓練とか、推論ができます。
Stable Diffusion。弊社の有名なモデルですけれども、いろんな綺麗な画像を作りますよね。もしかしてご存知の方はいらっしゃると思いますけれども、結構世界中でたくさん使われていますね。
で、やはりもう他の画像生成AIサービスも色々出てきていて。正直すごくクオリティの高い他社の画像生成もサービスありますよね。じゃあ、なんでその Stable Diffusion がまだこんなになんかシェアが高いかっていうと、やっぱり「オープンなモデル」で、あと「自由」。そこに基づいて、モデルを改善したり、調整したり、素材に基づいて研究したり、その Stable Diffusion の元となった論文ですね。「Latent Diffusion」、潜在拡散モデルっていう論文の著者の4人は弊社の社員で、その論文はもう4,000回以上引用されています。もちろん引用せずになんか色々改善してる人もいますけど。

日本でも結構マスの検索回数が多いですね。あと HuggingFace っていう、モデルをダウンロードするサイト、そのAIモデルのオンラインコミュニティとして、一番大きいプラットフォームがあるのですけれども、弊社はこの11月時点で Trending で一番多くの Like をいただいております。おかげさまで HuggngFace でトレーニングしてるモデルは1位も2位も弊社のモデルで、あ、4位も一応。オープンに出すことによって、結構いろんな人がすぐ遊びたいっていうのが楽しいですよね。
もうちょっと色んなモデルの話をしますと行動生成モデルですね。これを出した当時は多分最先端だったんですけれども、今はもう多分1位じゃないですけれども、もっといいのを作ります。
いろんな言語のそのオートコンプリートとか。これはそのオートコンプリート版とインストラクション版がありますね。

https://ja.stability.ai/blog/stablecode
Stable Audio。テキストを入力して音楽とか効果音サウンドを生成できるサービスですね。

これ拡散モデルのアルゴリズムを使っています。
(サンプルを再生)
https://stability.ai/stable-audio
これ無料だと45秒成、有料だと1分半です。いろんなモデル、今はもう、そのリーダーボードでは1位じゃなくなりましたけれども、いろんな言語モデル、日本語の言語モデル、そのベースモデルと「インストラクション版」支持応答バージョンを出していますね。あとトークナイザー、言語モデルの語彙を日本語に拡張して、日本語でより速く推論できるようなバージョンをリリースしたりしています。


けっこう色んなユーザーにニーズに合わせて、速く安く推論したいんだったら30億パラメータ。スリービリオン(3B)のモデルを使えばいいんです。

https://note.com/aicu/n/n6cf8beaf1439
これは弊社のま海外チームが作った3Bの英語モデルを日本語化させたものですね。結構「そのサイズにしては、多すぎるデータ」で訓練させた感じですね。もし性能重視だったら、70ビリオンのモデルを使っていただければ。
これちょっと才能最高性能って書いてあるんですけど、確か昨日ぐらいなんか追い越されたかも。
画像から言語を生成するモデル。どんどんマルチモーダルなモデルを弊社も色々出していくと思いますね。なんか先週も NeurIPS(ニューリプス)っていう。AIの会議でたくさんのマルチモーダル系の論文を見ましたけれども。

例えば「この写真は何?」って聞いたら「ラムネの旗が植えられたぎふや」とか。

チャット形式で「その風鈴に描かれているものは何ですか?」「魚」「席の色は?」「緑です」「人はいますか?誰もいません」みたいなやりとりができます。これは色んなユーケースがあって、例えばそのまま画像検索とか、商品検索のための画像生成とか。あと目の不自由な方の手伝いとか……色々できるかなと思います。
やってみた!
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) November 13, 2023
サンプルのソースコードによると
- caption: 画像を詳細に述べてください
- tag:与えられた単語を使って、画像を詳細に述べて
- vqa:与えられた画像を下に、質問に答えてください
VQAはすごい革新的、久々に感じる"革新"だわ!!
GoogleColabのT4ではなくA100で試してみて #JSVLM https://t.co/W4JSpFzze6 pic.twitter.com/LdtPUIZir0

あとこれは厳密に言えば、生成AIのモデルじゃないんですけれど「CLIP」、クリップっていうのは、言語と画像も同時に理解できます。いろんな生成AIのシステムの中で使われますし。普通の画像分類タスクにも使えます。

大元のStable Diffusion XLっていうのは英語から画像を生成するモデルですけれど、じゃあ「なんで日本語版の作る日本版を作る必要があるか」っていうこと聞かれるんですけれど。例えばそのままGoogle翻訳とかで、日本語から英語に翻訳させて入力すればいいじゃないですか。確かにそれでワークするケースも多いんですけれども、やっぱりそのままそれでやってたらバイアスがありますよね。
例えば「男子高校生のプロフィール写真」って入力したらやはり白人が出てきますよね。なので、そういうなんだろう……欧米のチームが作ったモデルだと、やっぱりそういう欧米のバイアスがあって。特にアメリカのバイアスがの言語モデルにおいても、画像モデルにおいても、ほとんどの世界的に有名なモデルにおいてはあるなと思っていて。なので、そのまま「高校生」って入れたら、日本人とか東洋人が出てくるようにしてほしいケースもあるかなと思います。
あと例えば「海岸沿いを走るライダー」っていうプロンプトだと、例えば「ライダー」を英語のなんか「rider」というように、なんか機械翻訳して欧米のニュアンスでいうと、通常「馬を乗る人」の意味ですけれども日本語でライダーっていうと、「バイクに乗る」ニュアンスが強いので。そういう、なんか「翻訳で失われる情報」もあるなと思います。
動画生成モデル「Stable Video Diffusion」。これは画像から動画を生成するモデルですね。実は、社内で「テキストから動画を生成するモデル」も持ってるんですけれども、ちょっとそのどういうふうにするかはちょっとわかりませんが、結構これは楽しいなと思いました(動画)。


あとリアルタイム画像生成ですね。これは敵対的拡散蒸留、Adversarial Diffusion Distillation (ADD) という名前で論文も出してます。どうやってやってるかアルゴリズムも公開してます。以前にLCM(訳注:Latent Consistency Models)っていう手法もあったんですけれども、それは大体4ステップから8ステップ。
LCMが人気だけど
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) December 22, 2023
StabilityAIのAdversarial Diffusion Distillation (ADD)はより根源的。もっと注目されるべき。https://t.co/vlWGKvixb8#CCSE2023
従来の Stable Diffusion XL は、その1回の生成、1枚の生成に、例えば40ステップを使ったんですけれども。LCMでは4~8ステップ。これ(ADD)だと1ステップから4ステップで、かなり品質の高い、本来の SDXL に遜色ないようなクオリティを出してます。で、それをさらにコミュニティが改造してて、昨日ぐらい、在米の日本人が1台のGPUで1秒あたり100枚の画像を生成する論文を出しています。
https://github.com/cumulo-autumn/StreamDiffusion/tree/main
あと3Dもけっこう楽しくて。これリギングとかアニメーションの部分をちょっと別のソフトでやったんですけども、その3Dモデル自体は、弊社のモデルで作りました。こちらのモデルをリードしている人は、もともとまGoogle Researchで似たような研究をしている方が、今このチームを率いています。

<後編に続きます!>
前編はこちら
いいなと思ったら応援しよう!
